こんにちは。スマートニュースの真幡です。
スマートニュースには海外カンファレンスへの参加をサポートする仕組みや、技術コミュニティへの会場提供を支援する仕組みがあります。
これらのおかげでスキルアップの機会には事欠きませんが、この他に社内でも無数の勉強会が開催されています。この記事ではスマートニュースの社内勉強会についてご紹介します。
スマートニュースの社内勉強会
スマートニュースの社内勉強会は多種多様です。
最も大規模なものは「SmartNews Tech Talk」と呼ばれるもので、社内の全エンジニアが参加します。参加者のバックグラウンドは多様なので、トピックとしては「キーボードの内部構造」や「ロードアベレージの解釈」であったり、「広告配信の最適化」のような、特定の業務知識を前提としないものが多いです。また、社外からゲストを招くこともあり、社内に閉じずに広い視野で技術動向をつかめる勉強会です。
この他にも、草の根的に社員がはじめる勉強会もあります。例えば技術書の読書会などは誰かが「やろうぜ」と言うことで、カジュアルにはじまります。

(社内で開催されている「SRE 本」読書会の様子)
また、少し異色ですが「寿司を食べてビールを飲みつつ任意のトピックについてハンズオン形式で学ぶ」勉強会も定期的に開催しています。以下では、この「寿司を食べて〜」の勉強会についてご説明します。
寿司を食べながらの勉強会
これまで、寿司を食べながら次のようなトピックについて勉強会を開催してきました。
- Docker と寿司とビール
- R と寿司とビール
- TensorFlow と寿司とビール
(補足: ビール以外のドリンクも準備しています)
スマートニュースではチームビルディングのための予算がチームに与えられます。「技術」をネタにわいわい勉強して教え合うことは広義のチームビルディングであるという考えのもと、寿司を食べながら勉強会を開催する習慣が根付きました。実際、勉強会を終えるごとにチーム間での共通語彙が増え、コミュニケーションが円滑になっているように感じます。
ハンズオン形式なこともチームビルディングに一役買っています。講師役のエンジニアが作った課題を、各メンバーが手を動かしながら解いていくのですが、バックグラウンドがまちまちなので、進捗ペースには個人差があります。たとえば、主としてフロントエンドを担当しているエンジニアにとって、Docker で意図通りのイメージを作ることは容易ではないかもしれません。その場合、となりのエンジニアと寿司をつまみながら「ここの Dockerfile のこの行がさ〜」などと話をしながら一緒に課題を解決していきます。この過程を通して、お互いが得意とする技術に対する理解も深まります。

TensorFlow と寿司とビール
「TensorFlow と寿司とビール」について、もう少し詳しくご紹介します。
マシンラーニング系のシステム全般を担当しているプロダクトマネージャに講師を担当してもらい、「Deep Learning 界の “Hello World”」こと画像分類器を作りました。
前準備としての画像収集
参加者には、事前準備として分類対象の画像を収集することを求められました。
あらかじめ準備されたハンズオン資料には Fatkun Batch Download Image を使うと「Google 画像検索」の結果から画像を一括でダウンロードできて便利だという案内がありました。同僚のひとりが、この Chrome 拡張で「あだち充マンガのヒロイン分類器」を作ろうと画策したものの、本人がヒロインを区別できず教師データを作れなかったため、そのプランはお蔵入りしました。
イントロとしての「TensorFlow Dev Summit 2018」振り返り
勉強会のイントロとして、数ヶ月前に講師が参加した TensorFlow Dev Summit 2018 のキーノートを振り返りました。
Google の Jeff Dean 氏による、次のスライドに込められた主張は特に興味深いと思います。
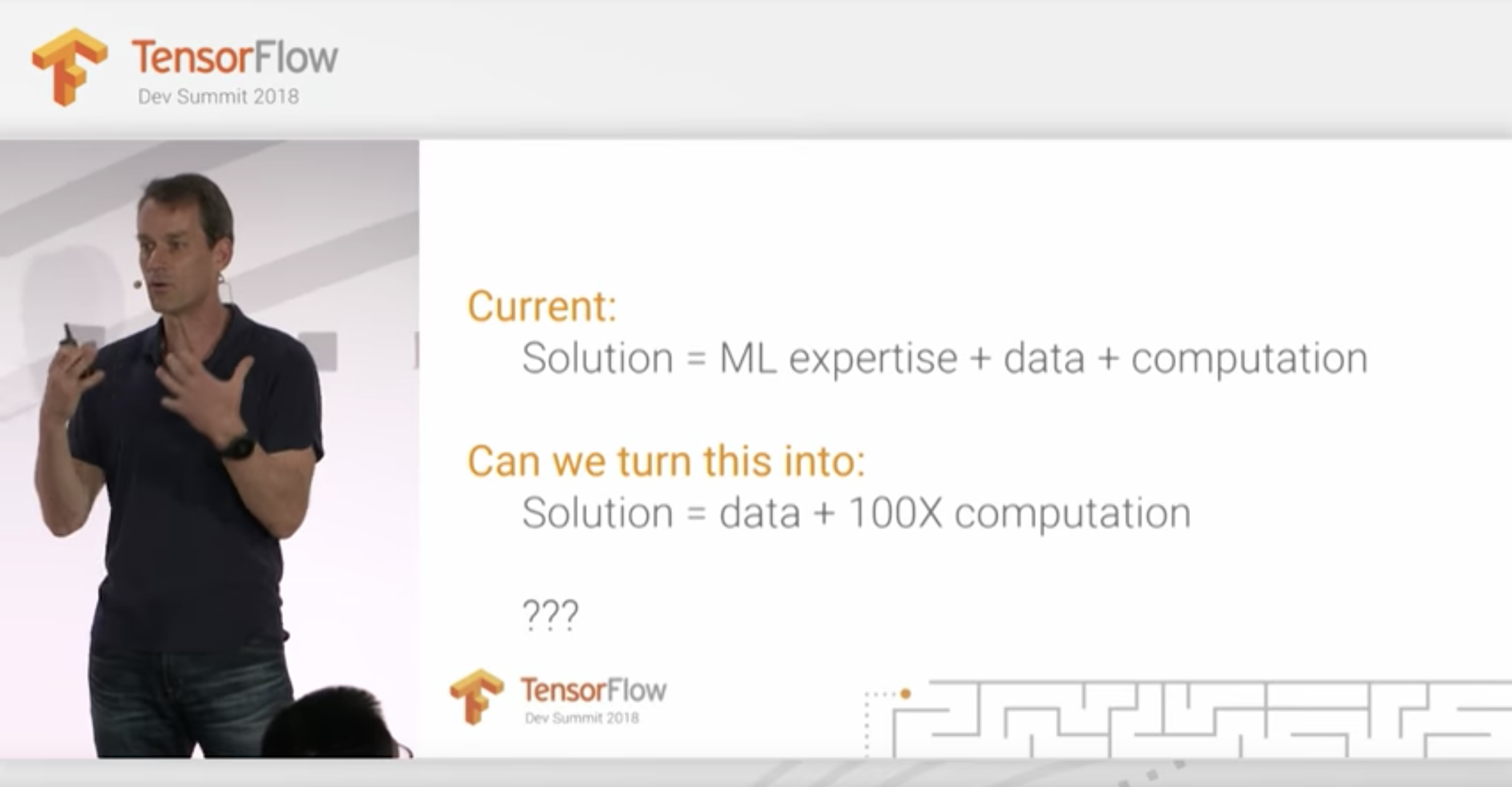
現在は問題解決のために「ML の専門知識 + データ + 計算機リソース」が必要だが、この代わりに「データと100倍の計算機リソース」で問題解決できないだろうか、という主張です。つまり、十分なデータさえあれば、小難しい ML の知識がなくても Deep Learning で目的を達成できないだろうか、という発想です。
わたしを含めて、ハンズオンを受けたエンジニアの大部分は ML の専門家ではありませんでしたが、無事に TensorFlow で画像の分類機を作ることができました。このことを考えても Jeff 氏の発言には一定の説得力があると感じました。
以下、最近入社した同僚の感想です (わたしも同じように感じました):
今日、 TensorFlow 勉強しながら寿司食べる勉強会で習ったんだけど、以下の tutorial の https://t.co/DBkso6Mexh だけで色んなものに使えてすごい。民主化されてる感ある https://t.co/NSL3dKQbqx
— あまの (@amachang) April 27, 2018
SageMaker による機械学習
環境として、AWS のマネージドな機械学習サービスである SageMaker を使いました。
SageMaker のコンポーネントのひとつとして Jupyter Notebook があり、ほとんどの作業はこの上で行いました。
SageMaker では次のような操作をしました。
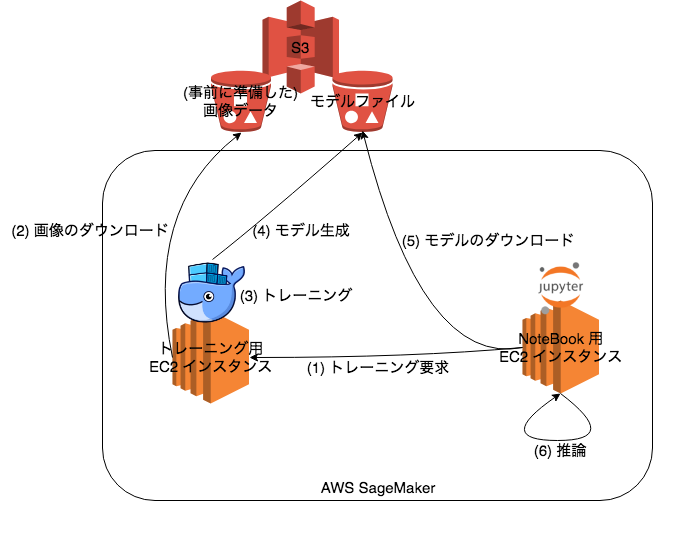
SageMaker では Jupyter Notebook を動かすインスタンスと、トレーニング用のインスタンスを別々に起動できます。Notebook はあらかじめ講師に準備してもらい、それを少しずつ変更しながら動かしました。Amazon SageMaker Python SDK の Estimator のコンストラクタは第一引数でトレーニング用のコンテナイメージを受け取るので、TensorFlow の GitHub リポジトリにサンプルとして含まれている retrain.py や、TensorFlow の実行環境を含む Docker イメージをあらかじめ ECR に準備しました。これにより、環境構築の手間を最小限にしてハンズオンそのものに集中できました。
Docker でトレーニングした結果のモデルは S3 にアップロードし、Notebook インスタンスでそれを取り込んで画像分類機を動かしました。
ハンズオンで作った分類器のご紹介
フォント分類器
フォントかるたをご存知でしょうか?
【RT希望】『フォントかるた』Amazonでの販売を開始しました!全国のマニア(?)の元に届きますように!(2号)https://t.co/5bUlA25j3g#フォントかるた#Amazon pic.twitter.com/4K08W3GKFB
— フォントかるた (@font_karuta) June 20, 2017
「愛のあるユニークで豊かな書体。」と書かれた札のフォントを当てるカルタです。当社でも (一部で) 流行しているこのゲームで、無敵の力を手に入れるためにフォント画像分類機を作成したメンバーがいました。

12種類のフォントに対して100枚ずつの画像で学習して分類器を作ったところ、まずまずの精度が出る分類器ができました。
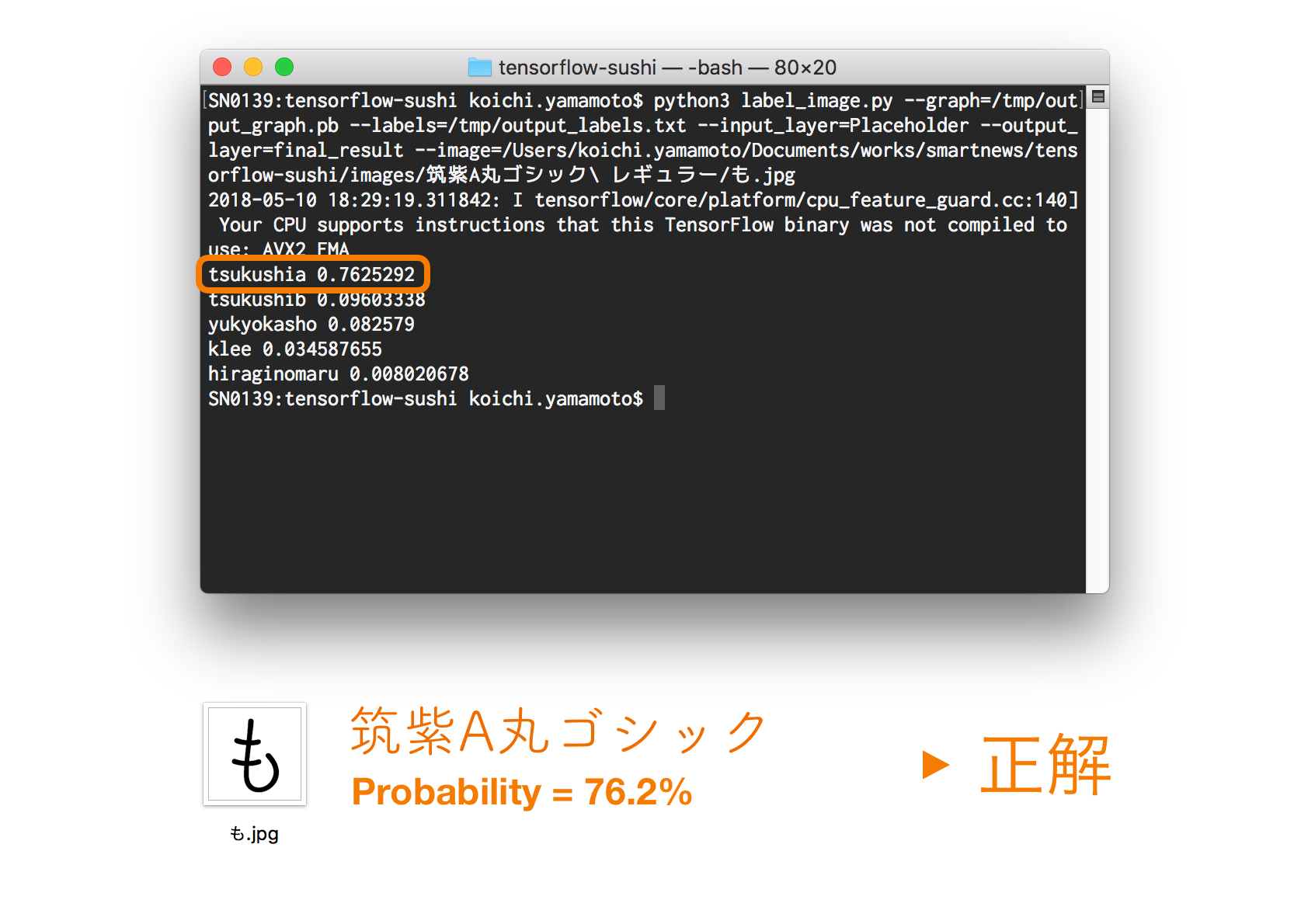
(この例では分類機をローカルで動かしています)
植物画像の分類器
「ひのき」や「すぎ」などの植物画像の分類器を作成したメンバーがいました。作者は当社のモバイルエンジニアで、サーバー側で作成したモデルを CoreML 変換して iOS アプリで推論するところまで作り込みました。

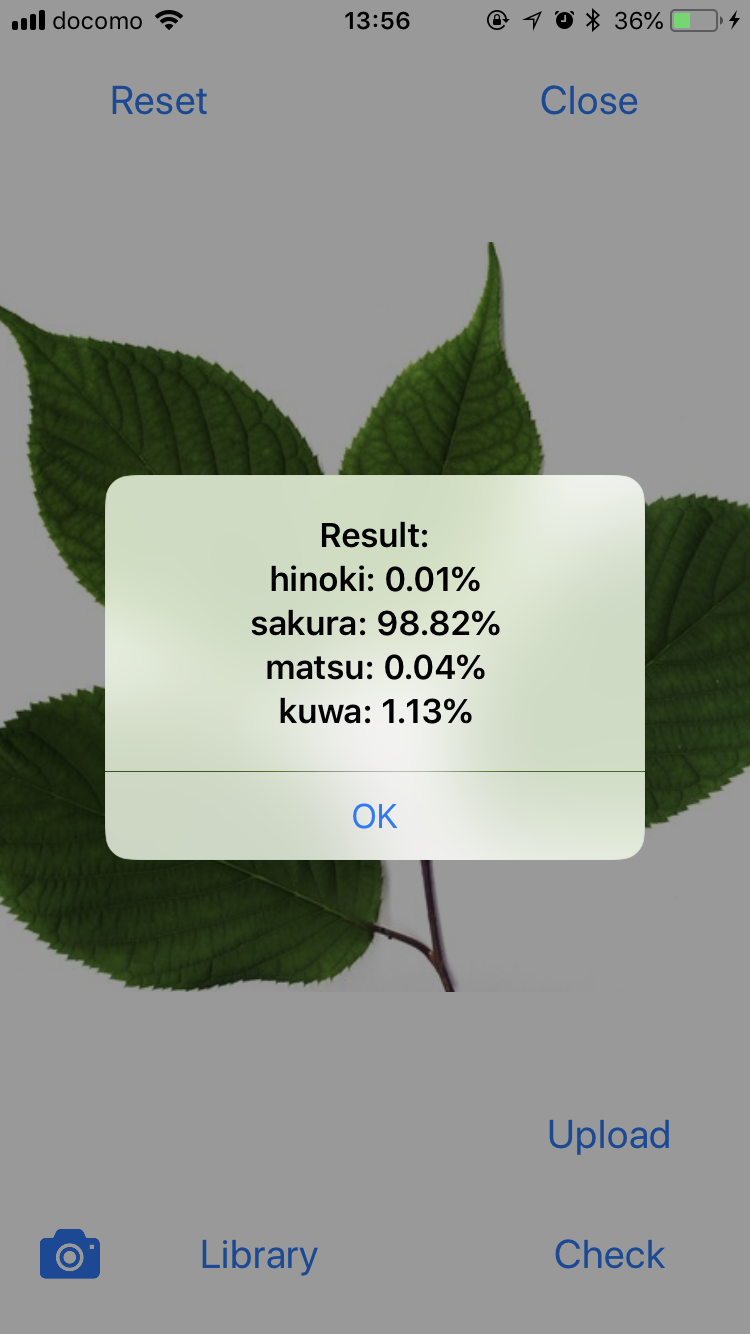
これについては、技術的な詳細を別な記事にして紹介する予定です。
その他の分類器
他にも、次のような画像分類器ができました。
- たい焼き画像とパンケーキ分類器 (わたし): たい焼きとパンケーキを間違えないように。
- 動物画像の分類器: アヒル、つばめ、ペンギンなどのかわいい動物たちの分類器。高い精度で分類できた。
- QR コード画像と通常の画像の分類器: 過去に作った UGC サービスで QR コードをアプロードするユーザーがおり、自動的に排除するツールがほしかった。TensorFlow で簡単に実現できた。
- ウィスキー画像の分類器: ウィスキーのボトル画像から、銘柄をあてる分類器を作った。ただし、「Laphroaig」を「Bunnahabhain」と判定するなど、精度はいまひとつ。
SageMaker を使ったハンズオン形式勉強会のハマりどころ
AWS で GPU 特化型のインスタンスと言えば P シリーズです (P3 や P2)。勉強会の開催日のタイミングでは AWS SageMaker は東京リージョンに来ておらず、バージニア北部リージョンで SageMaker を使うことにしました。ところが、このリージョンでは P3 や P2 のインスタンス数の上限緩和申請をしておらず、P シリーズのインスタンスを取れないメンバーが出てしまい、先にインスタンスをつかんだ人がトレーニングを終えるまで「待ち」になってしまうことがありました。
SageMaker のようなマネージド環境は、環境構築が楽ではあるものの、ハンズオンの前に「実際の規模で」リハーサルをすることが難しいので、そこは難しいところだと思いました。
いっしょに寿司など嗜みませんか?
スマートニュースでは、寿司を食べたり食べなかったりしながら一緒にわいわい勉強しあえる素敵な仲間を募集しております。色々なポジションで絶賛採用中なので、ぜひ採用ページをご一読ください。