はじめに
こんにちは。スマートニュースの大平です。主にさだまさしに関するネタが切れたために、こちらのブログではしばらくご無沙汰でした。さだまさしといえばみなさんご存知の通り、デビュー40周年を超え、創りだされた楽曲は500曲以上、ソロコンサートの回数はゆうに4100回を超え、還暦を超えた今でも年間100回前後のコンサートを重ねる、現代歌謡界におけるレジェンド的な存在です。
とはいえ40年の間さだまさしは常に同じ姿のまま過ごしてきた訳ではありません。たとえば、彼は声帯を痛めるなどの要因もあり今まで大きく分けて3回ほど発声方法を変えています。ここで詳述するといろいろ苦情が来そうなので短くまとめると、声帯を痛める毎に喉に負担がかからず体全体で声を出すような歌唱法に変えたため、今は昔のような高音で華麗な歌声ではないですが、オペラ歌手のような太くて堅牢な声になり、結果以前よりたくましく、還暦とは思えないペースで音楽活動を続けています。
この例からも分かるように、コンサートという名の instance を継続的に provisioning し、楽曲というプログラムを deploy し続けるためには、その時々に応じて不断の努力と変化が必要となります。
背景
だいぶネタ振りに強引さがありましたが、ご了承ください。弊社内での provisioning ~ deploy の仕組みについては、以前下記のような記事を書かせていただきました。
ただこちらは2年ほど前の仕組みになります。漸進的に改良は加えてきましたが、運用を重ね、人も増える中で、いくつかの問題が生じてきました。
Chef の recipe の散在化
これは多くの人が経験されていることかもしれないですが、複数人で Chef の recipe を触るような環境だと、よほどしっかりした運用ルールや規約が存在しないと、各人・各プロジェクトで独自の書式や振る舞いを記述したり、もしくは同じような記述があちこちに散在したりと、収集がつかなくなります。 Chef が比較的大きめで自由な仕組みであったこともあり、かつ弊社内での規約も不十分だったこともあり、社内でその散在化の度合いはとても大きかったため、一度、シンプルな仕組みで再整理する必要性が出てきました。運用の職人化
プロジェクトによっては、ナイーブに package を配布しミドルウェアを再起動するだけで deploy 完了になるプロジェクトもありますし、1台だけ deploy をして主に負荷的な様子を見てから全台に適用するような運用をしているプロジェクトもありましたが、それらは運用する各人の職人技に委ねられており、システム的な手順として表現されているものではありませんでした。 そのため deploy 作業についても属人性が残り、プロジェクト外の人がおいそれと触れる状態ではありませんでした。陳腐化
Chef / Fabric を用いた半自動的 deploy フローというものも当時はそこそこトレンドに追随していた気もしますが、今となっては環境の変化、主に SaaS の充実や AWS などのクラウドサービスの機能追加により、より高度に自動化した環境を構築しやすい環境が整ってきました。それらを踏まえて deploy フローの見直し
これらの状況を踏まえて、半年前ほどから、provisioning ~ deploy のフローについての見直しプロジェクトが動き出しました。 そこで目的としたことは以下のようなものです。- provisioning ~ deploy フローを自動化する
- 属人性を極力無くし、deploy作業から人的リソースを解放する
- たとえば、画面もしくはコマンドで数字を変更することで、柔軟にサーバー台数の調整が行える
- たとえば、 repository server の master に修正コードを push したら自動的に production 環境に deploy してほしい
全体像
一般的なプロジェクト構成
はじめに、弊社の server-side program は、一部例外(RoR, golang, c++, etc)もありますが、大半は Java8 で書かれています。 Java においては、プログラムを War と呼ばれる web application container に配布するための package 形式や、Jarと呼ばれる library package 形式にまとめて所定の場所に配置するのが、一般的な deploy の方法になります。deployフロー
その上で、新しく作り上げた deploy フローについて、雑な絵になりますが概略図を以下に示します。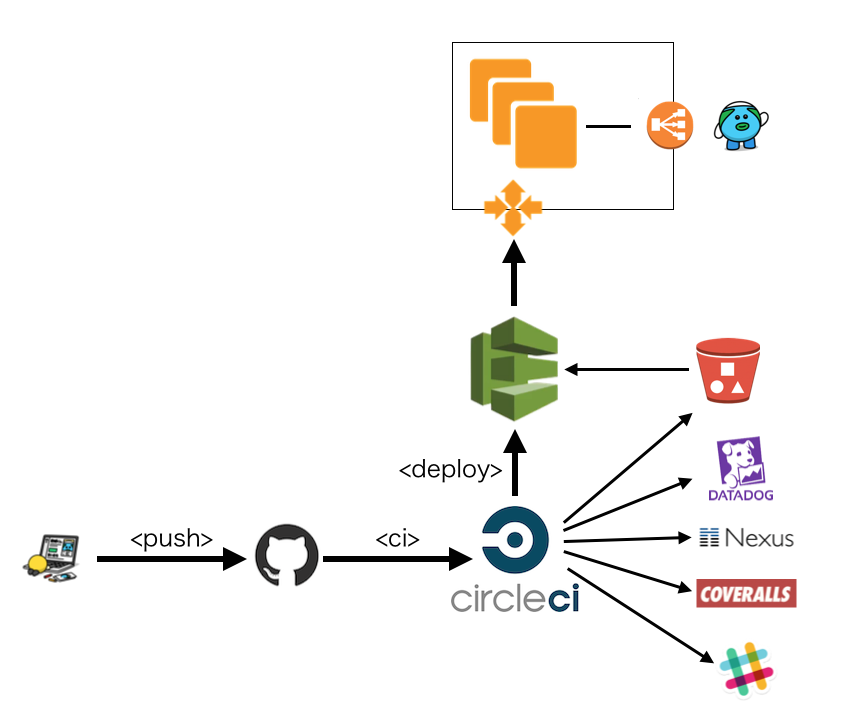
主要な登場人物は
- Itamae
- Auto Scaling
- CodeDeploy
- GitHub / Circle CI
Itamae
https://github.com/itamae-kitchen/itamaeItamae は @ryot_a_rai さんが作られた LightWeight な Chef like な OSS です。Chef で実現できた事のうち、 recipes の部分のみを切り出したようなシンプルなツールになっています。
 (こちらの発表資料より引用)
(こちらの発表資料より引用)
弊社内で蓄積された Chef 関連のリソースを再利用・再整理するために粒度がちょうど良かったこともあり、Itamae を用いて provisioning の定義を書き直すことにしました。
Auto Scaling(Launch Configuration / ASG)

AWS のサービスをお使いの方にはお馴染みの Auto Scaling です。Auto Scaling は仕組み的には、サーバーの起動設定を定義する Launch Configuration と、起動台数などクラスターグループの管理を行う Auto Scaling Group(ASG) により構成されます。
弊社ではいわゆるイベントに応じた Auto Scaling 処理の用途とともに、特定のプロジェクトのインスタンス群をグルーピングする単位として用いています。
ASG と itamae の integration
社内の規約として、Launch Configuration で使用する AMI は自分たちで必要そうなミドルウェアや shell scripts をあらかじめ含めてパッケージしたものを使用しています。#!/bin/bash
ID=$(wget -q -O - http://169.254.169.254/latest/meta-data/instance-id)
REF=$(aws --region ap-northeast-1 ec2 describe-tags --filters "Name=resource-id,Values=${ID}" "Name=key,Values=Ref" | jq -r ".Tags[].Value")
REF=${REF:-master}
echo "instance-id: ${ID}"
echo "ref: ${REF}"
/hoge/fuga/itamae.sh ${REF}
その上で、上記のような shell script を Launch Configuration の userdata として登録します。 インスタンス起動時にこちらが実行され、itamae.sh によりサーバーの provisioning が自動的に行われる、という流れになっています。
ASG のグルーピング
以下は一例ですが、様々なユースケースでグルーピングを行っています。- 環境により分ける(development / staging / production)
- 適用したいツールにより分ける
- production のうち NewRelic を有効にする ASG
- NewRelic を無効にする ASG
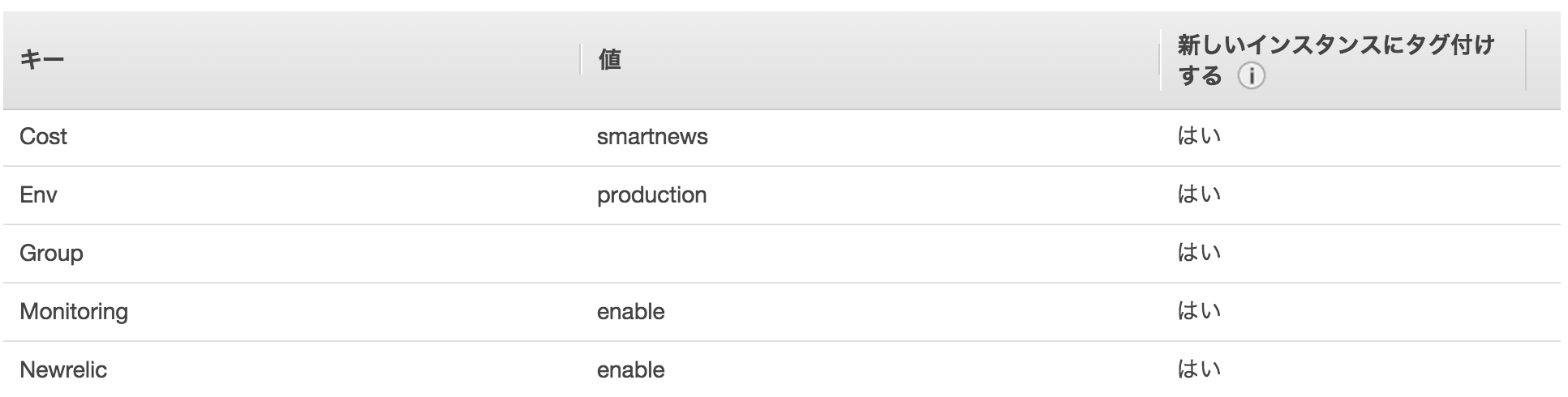
処理の振り分けは上記の画像のように ASG のタグにより行っています。こちらは作成された EC2 instance にも引き継がれ、instance の初期化時に上述のように Itamae による provisioning が行われますが、その際にタグを参照して振る舞いを変えるようになっています。 (上記画像は、NewRelic を有効にする ASG の例です)
Code Deploy
http://aws.typepad.com/aws_japan/2014/11/new-aws-tools-for-code-management-and-deployment.html
CodeDeployは AWS のサービスの中では比較的新しいもので、日本では2015年8月から使用可能になりました。端的に言うとdeployフローを自動化してくれる仕組みを提供してくれるサービスです。
CodeDeploy の仕組みと deploy の流れ
revisionという単位でまとめられたパッケージに以下のファイルを含め、CodeDeployに命令を送ることで、所定の環境に deploy 処理を行うことができます。- appspec.yml
- deploy処理時に実行する処理定義
- scripts
- 実際に実行する処理
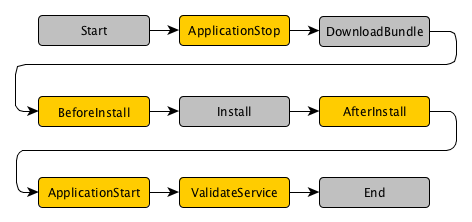
(こちらのドキュメントより引用)
上記のうち、以下の5つのフェーズについては、appspec.yml に hook 処理を記述することで任意の処理を行うことが可能になっています。
- ApplicationStop
- BeforeInstall
- AfterInstall
- ApplicationStart
- ValidateService
version: 0.0
os: linux
files:
- source: sample.war
destination: /var/lib/
hooks:
ApplicationStop:
- location: scripts/elb_deregister.sh
timeout: 30
- location: scripts/stop.sh
timeout: 30
BeforeInstall:
- location: scripts/cleanup.sh
timeout: 10
ApplicationStart:
- location: scripts/start.sh
timeout: 30
- location: scripts/elb_register.sh
timeout: 30
一度に deploy 処理を行う台数
CodeDeploy では、標準で以下の deploy strategy が定義されています。- CodeDeployDefault.OneAtATime
- 1台づつ deploy
- CodeDeployDefault.AllAtOnce
- 全台一斉に deploy
- CodeDeployDefault.HalfAtATime
- 全台のうち半分ずつ deploy
CodeDeploy と ASG の integration
CodeDeploy による deploy 先の環境には EC2 、もしくは ASG が指定できます。 弊社は上述のように環境のグルーピングに ASG を用いていることもあり、deploy 先には ASG を指定するようにしています。more information
Code Deploy の事例については、先日 @takus が勉強会で発表をした資料もありますので、より詳しく知りたい方はこちらもご参照ください。server_admin
上述の Auto Scaling や CodeDeploy の定義を Web Console や API を介して作成しても良いのですが、何度も同じ作業を繰り返す事は手間ですし、ある程度規約を設けないとさまざまな定義が混在してしまいます。作業の軽量化とある程度共通の規約で縛ることを目的に、 ASG や Launch Configuration, CodeDeploy の作成・編集を行える内製ツール sever_admin を開発しました。
(ちなみに実際に開発したのは @nobu666 です)
こちらを用いる事で上述の Auto Scaling や CodeDeploy に関する定義の作成を 1 liner で行えるようになり、非常に重宝しています。
server_admin asg create \
--group hoge \
--env development \
--instance-type t2.medium \
--subnet-id subnet-...... \
--volume-size 20 \
--no-newrelic \
--cost fuga \
--min-size 1 \
--max-size 10 \
--desired-capacity 1 \
--with-elb \
--security-groups sg-.....
GitHub / CircleCI


上述のように、サーバーの provisioning と deploy を行う流れが一通り整いましたが、実際の deploy 作業を手動で行いたくないため、GitHub / Circle CI と連携し、任意の branch に push したタイミングで deploy が行われるようにします。
現在、弊社では GitHub との親和性の高さから Circle CI を徐々に使用し始めています。ご存知の方も多いとは思いますが、Circle CI では circle.yml という定義ファイルに定義を書くことで、任意のタイミングで任意の処理を実施することができるため、こちらを使用して各種システムとの連携を行っています。
弊社では、主に以下のような処理を circle.yml 内で記述しています。
- slack への通知
- Datadog へのリリースイベントの通知

- nexus への jar / war の登録
- maven-release-plugin を使用
- coveralls に code coverage 情報を登録
- CodeDeploy への deploy 処理
test:
override:
- mvn -DrepoToken=${COVERALLS_REPO_TOKEN} cobertura:cobertura coveralls:report
deployment:
default:
branch: /^(?!^(master|develop)$).+$/
commands:
- bash ci/release.sh
development:
branch: develop
commands:
- bash ci/snapshot_release.sh
- bash ci/release.sh
- bash ci/deploy.sh
production:
branch: master
commands:
- bash ci/maven_release.sh
- bash ci/release.sh
- bash ci/deploy.sh
以上で、 GitHub の特定の branch に push することで、自動的に各環境に AutoDeploy される仕組みが整いました。
導入してみて
一部プロジェクトから導入を開始して数ヶ月になりますが、概ね大きな問題は発生していません。 サーバー構築作業、ならびに deploy 作業がほぼ自動化されることで、人的リソースの解放という意味で非常に大きな恩恵を得ています。また、手作業の介在する余地が減ったことが、手作業で運用していた際に発生していたしょうもないイージーミスを抑制することにもつながっています。ということで概ね満足をしているのですが、新たな環境に際して感じる課題点について、いくつか記載します。
test の重要性
master に push したら production に自動的に deploy される、という処理はとても利便性が高いですが、バグを含むコードが不用意に公開されてしまうリスクと隣りあわせです。 この環境を本当の意味で安全に運用するためには、test を厳密に用意し、 test phase でバグや意図せぬ変更を事前に検知できるようにする必要があります。 正直、弊社の test coverage はあまり誇れる状態ではないので、今後 test coverage について目標値を定めたり、testに対するリテラシーをエンジニアたちが向上できるように集中合宿(test offsite)などを実施する予定です。naming convention の重要性
以前弊社で Chef を運用していたときに感じたことでもあるのですが、自由度をもたせすぎると、その自由度の範囲で各人が各人の判断をしがちです。また、前例や頼るべき規約がないと、毎回同じような個所で不要に頭を使い、時間をロスしたりしてしまいます。という意味で、規約というのはとても大事で、そのうち名前付けに関する規約というのは一番分かりやすく整理しやすい部分かなと思います。
弊社では、この deploy フローの再整備にあたって、EC2 や ELB の命名規則や ASG や CodeDeploy の命名規則、各 environment の命名規約(短縮形: prd/stg/dev や非短縮形: production/staging/development)の整理を事前に行ったうえで作業を進めましたが、より広く多様に運用していくためにさらなる整備と見直しが必要だと感じています。
 (上記は規約についてまとめた社内 Qiita:Team の記事です)
(上記は規約についてまとめた社内 Qiita:Team の記事です)
監視処理との連携
実際のところ、deploy フローは自動化されましたが、とはいっても deploy 時に push して後は放置というわけにも行かず、deploy 作業時は datadog や NewRelic などのメトリクスを注視して異常がないかの確認は常に行っています。監視システムとして、正常/異常な状態を正しく定義できれば、ここまで人的リソースを用いて注視をする必要もないため、監視システムについても deploy フローにあわせて刷新をしていく必要があるかなと考えています。
special thanks for takus and nobu666
ちなみに、この deploy フローについて、私の方で偉そうに記事を書いてきましたが、実際にこの環境を構築するのは @takus ならびに @nobu666 両名の功績が大きく、素晴らしい物を作ってくれました。 (私が行ったことは、ブログ向けに文章を整えたのみです…) この場を借りて、この両名には感謝の意を述べたいと思います。また、このプロジェクトはトップダウンで実施したというよりは、チームメンバー間で日々の課題について協議をしたうえで「やるべきだ」という合意のもと、方向性を決めて、いっきにやり遂げたタスクになります。この事例から、弊社のエンジニアが主体的に活き活きと課題にタックルし、クールな解決策を考え、取り組んでいる、そんな仕事の姿の片鱗を感じていただけますと幸いです。
板前を provisioning しました
ここからは余談になります。先日、Itamae などを用いた deploy フロー刷新を祝して、リアルな板前を provisioning して、握りたてのお寿司を hot deploy していただき、ささやかなパーティを社内で執り行いました。




熟練の職人の手で次々と deploy されていく良質なお寿司を見ているだけで楽しい気持ちになりますが、我々としては職業柄、自分たちの仕事の中で機械で行える処理についてはできるだけ自動化していきたいなと思っております。
さいごに
弊社スマートニュースではエンジニアを随時募集しております。 お寿司はめったに振る舞われませんが、社食(SmartKitchen)が6月より始まり、ヘルシーな昼食を楽しんでいただけますので、弊社に少しでも興味がある方はぜひお誘い合わせの上、遊びにきていただけると嬉しいです。