ゴクロの大平と申します。はじめまして。 4月からjoinさせていただいた、特に特記事項の無い平凡なプログラマです。さだまさしが好きです。
SmartNews開発者ブログをご覧になる方々は、サービスの裏側で動作するクローラーや多種多様な機械学習のロジックであったり、フロントエンドのUIの話であったり、サービス固有の話に興味が有る方が多いと存じますが、都合上(原稿の担当順番の都合上)、今回は一般的な話をさせていただきます。 ※先掲の話題については次回以降取り上げられますので、お楽しみに。
一般的な話題とはいえ、大企業とスタートアップでは取り巻く環境や解決すべき課題も異なっていますので、その辺もあわせてお伝え出来ればなと思います。
なお、今回のテーマは、サーバー/ミドルウェアの構成管理ツールとして最近有名になってきた「chef」と「fabric」です。 かなり長文のエントリーになってしまい恐縮ですが、ご了承ください。
スタートアップを取り巻く環境
スタートアップは各種リソースが不足しております。たとえばサービスを提供するためのサーバー環境は初期投資の負担が多いためiDCとの個別契約ではなく、AWSのようなクラウドサービスを使用しています。これは良し悪しで、長期的に観た場合クラウドサービスは割高かもしれませんが、初期投資の負担を少なくできますし、用意されているAPI等の便利な機能を用いることで少人数で多くのサーバーをコントロールできるようになります。 そのような事情もあり、弊社は4名の技術者が所属していますが(※2013年7月8日現在)、インフラ専任の技術者は一人もいません。こういった状況下では、サーバー管理に必要となる要件は以下です。
- 技術者ひとりあたり多くのサーバーを管理する必要がある
- インフラ専任の技術者がいなくても誰でもサーバーを管理できるようにする必要がある
おそらくchefやfabricといったツールが昨今注目度を高めているのも、私どもと同じような状況におかれた方々が多いから、という事情もあると思います。
chef

http://www.opscode.com/chef/ chefはruby製のサーバー管理ツールです。”cookbook”や”recipe”といった単位でサーバーのあるべき姿を記述し、その内容にサーバーの構成を適合させる事を目的としたツール、とでも言えば良いでしょうか…? chefについての詳細な説明は、数年前からサイバーエージェントの並河さんなどが各所で啓蒙活動?をされているので、こちらの記事では割愛させていただきます。 参考:http://ameblo.jp/principia-ca/entry-10775775095.html 参考:http://www.slideshare.net/namikawa/devsumi2012-pigglife-chef
今年に入って伊藤直也さんが大変わかりやすいchef-soloの本を出版したりと、一般の方々にも認知がされてきているようですね。

chefの使用方法
弊社では現在はまだchef-serverは導入しておらず、基本的にchef-soloで運用しています。ただ、各サーバー上へのchefインストールや、サーバーごとにchef-soloコマンドを実行して回るのは作業的に面倒なので、knife solo を用いて当該サーバーにリモートから接続しchefのインストールとrecipeの実行を行なっています。knife soloでは、まず”prepare”コマンドを実行して対象サーバーにchefをインストールし、”cook”コマンドにてrecipe群の実行を行います。
$ knife solo prepare hoge@hoge -V
$ knife solo cook hoge@hoge nodes/hoge.json -V
chefのcookbookやrecipeは自作したものを社内のsource repositoryサーバー(bitbucket)に登録して使用するか、もしくはopscodeのサイトで提供されている3rd. partyのものを使用しています。
chefの適用範囲
弊社ではおおまかに言って以下3つの用途でchefを使用しています。- サーバーの初期環境構築
- ミドルウェアインストール
- カーネルパラメータ設定
- セキュリティ設定
- 時刻合わせ
- ログローテーション設定
- 監視ツール設定 等
- サーバーの定期的な設定変更
- ミドルウェアの設定変更と反映 等
- アプリケーションのリリース
- maven releaseを用いてrepositoryサーバーへJavaアプリケーションを登録
初期環境構築では、ミドルウェアのセットアップなど、サーバーの初期設定を行います。 定期的な設定更新作業と初期環境構築を分けているのは、それぞれ作業のスコープが大きく異なり、出来るだけ日常的な作業については処理時間を短縮するためです。 現在使用しているknife soloでは、コマンドを実行したサーバーからchef関連の各種設定ファイルをrsyncで作業対象サーバーにコピーし、chef-soloを実行します。この転送処理のオーバーヘッドがサーバー台数が増えると意外に馬鹿にならないため、1回しか行わなくて良い作業と繰り返し行われる作業は出来る限り分離しています。 また、3rd. party製のミドルウェアインストール用のcookbookの多くがサーバーの起動・停止を強制的に行うため、それらはサービス稼働中に容易に動作させ辛いので初回のみ実施したい、という理由もあります。
アプリケーションのリリース作業はコンパイル言語特有の事情です。弊社はJavaで多くのアプリケーションを開発していますが、リリース可能な状況にするためにbitbucketから取得したリリース対象のソース群をjarやwarといった形式にパッケージ化した上でpackage repositoryサーバー(nexus)に登録する必要があり、こちらの作業にchefを用いています。
vagrant-aws + chef で動作確認
chefの動作確認にはvagrant-awsとchefを組み合わせて行なっています。実際にサービスで使用されているAWSのamiを用いて環境構築することで、本番とほぼ同等の環境下、chefの動作確認が行えるため非常に便利です。vagrant-awsについての詳細は伊藤直也さんのブログが非常に良い情報源となっているので当記事での解説は割愛します。 参考:http://d.hatena.ne.jp/naoya/20130315/1363340698
chefは必要?AWSであればamiの再利用で良いのでは?
そういう意見をたまに耳にしますが、確かに環境の変更がほとんど行われない、設定的にも負荷的にも安定しているシステムに関しては、基礎となるamiを用意し、サーバー増の場合はそれを再利用する形の運用で問題無いと思います。ただ、日々のアクセス増に対応するためにチューニングや構成変更が必要であったり、アプリケーションのリリース回数が多いサービスでは、設定ファイルの変更も日々行われますし、それらの変更を迅速に多数のサーバーに適合させていく必要もあります。 変化が多い環境でも柔軟に環境を構築していくために、仮想イメージのコピーと合わせて、chefなどによる外部注入型の環境構築ツールも組み合わせて行くのがベターと考えています。
fabric

capistranoとの差
似たようなツールでruby製のcapistranoがあります。chefがruby製なので構成管理ツールはrubyで揃えようと思っていたのですが、capistranoは複数サーバーに一斉に同一コマンドを発行させたい場合、並列にしか実行できないのが障壁になりました。(A,B,Cというサーバーで”a”というコマンドを実行させたい場合、A→B→Cという感じで直列処理をさせることが難しい) fabricは基本直列で動作し、並列動作もオプションにより可能です。#直列で"hello"を実行
$ fab -H server1,server2,server3 hello
#並列で"hello"を実行
$ fab -H server1,server2,server3 -P hello
#二台ずつ並列で"hello"を実行
$ fab -H server1,server2,server3 -P -z2 hello
今回のfabricの用途は、サーバーの再起動や、アプリケーションのデプロイ作業を想定していたので、利便性からfabricを採用しました。
fabricの適用範囲
弊社では以下の用途でfabricを使用しています。- ミドルウェア群の再起動
- ロードバランサーからの切り離し/復帰
- ミドルウェアの停止/起動 等
- アプリケーションのデプロイ
- nexus repositoryから所定のバージョンのパッケージを取得し、配置
- 既存のパッケージのバックアップ
- 他、サーバー上での作業
複数サーバーへのfabricの実行
fabricは接続先のサーバーを”-H”オプションで指定しますが、接続対象がたくさんある場合、手で情報を入力していくのは大変です。 弊社では、AWS上のサーバーについては以下の様な形で接続先情報を自動で取得するようにしています。- ec2 instanceのtag情報に、ロールごとに一意の値を入力(たとえばsmartnewsのwebサーバーであれば”smartnews-web”)
- fabricで特定ロール全台に一斉で作業する場合、AWSのAPI経由で所定のtagに合致するサーバー情報を取得する
- 取得したサーバーに対して各種処理を実行
conn = boto.ec2.connect_to_region(env.region, aws_access_key_id=env.access_key_id,aws_secret_access_key=env.access_secret_key)
reservations = conn.get_all_instances(filters={'tag-key':'Group', 'tag-value': env.group_name})
instances = []
for reservation in reservations:
for instance in reservation.instances:
if instance.public_dns_name:
instances.append(instance.public_dns_name)
elif instance.ip_address:
instances.append( instance.ip_address )
env.hosts = instances
chef + fabricを用いた実際の事例
上記のような環境整備を、入社後半月くらいかけて実施した結果、日常的な作業も楽になりましたし、既存の環境を変更したり新規に多数のサーバーを一斉に起動する事に恐怖感がなくなり、アクティブな使い方ができるようになりました。 その辺の事例をいくつかご紹介したいと思います。アプリケーションのデプロイ
まずはじめに、ありふれた日常的な作業の一例として弊社のアプリケーションデプロイフローをご紹介します。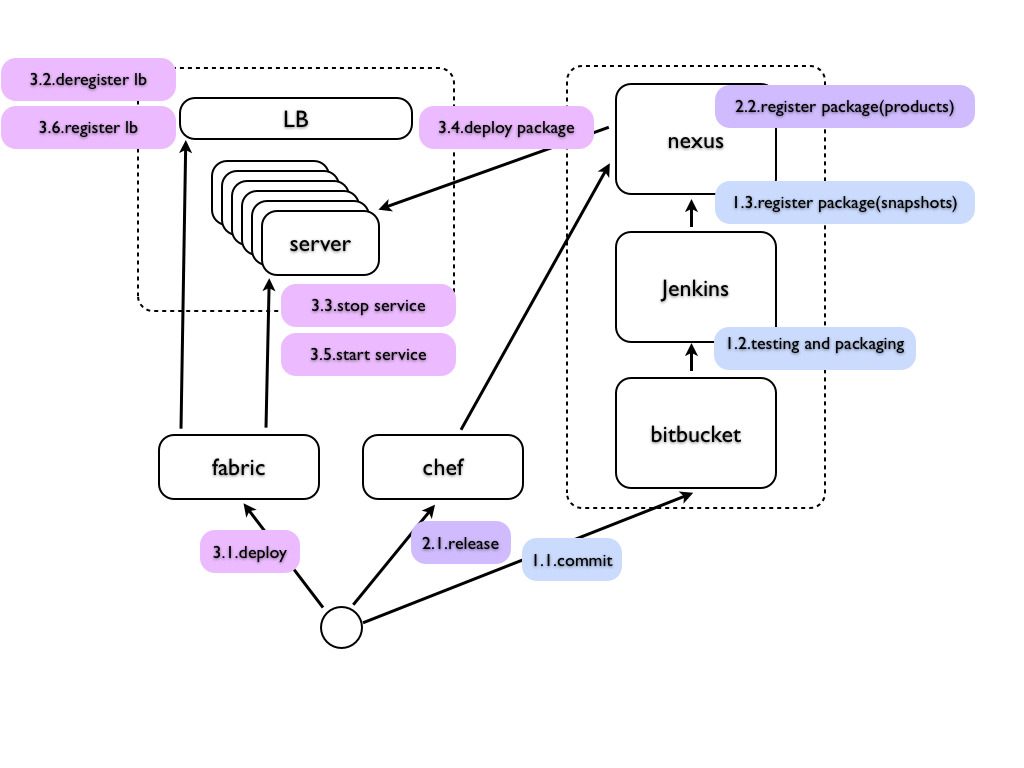
日々開発しているアプリケーションのソースは、bitbucketにpushされたタイミングでJenkinsによりtestの実行や各種メトリクスの取得を行った上で、testがall greenであればsnapshotパッケージが自動的にnexusに登録されます。
これとは別に、リリース対象のソースについてはchefを用いて手動でリリース作業を行います。これによりproduction向けパッケージがnexusに登録されます。CIツールで自動的にリリース作業が行われるのはリスクが多少あるため、このような手動実行にしております。
その上で、fabricを用い、サービスの再起動と、アプリケーションのデプロイを行います。デプロイ対象のパッケージはnexusより取得します。デプロイ作業中ではロードバランサーからの切り離し/復帰作業や、サービスの停止/起動作業もfabricのタスクとしてあわせて行われます。
これら一連の作業をchefやfabricを通して行うため、リリースに関する諸々の作業がだいぶ自動化・簡略化できました。
大規模負荷試験の実施
あまり一般的でない事例も紹介します。 弊社でとある機能リリースを行う際に、リリース後大量のトラフィックが発生することが想定されていたため、事前に入念に負荷試験を実施する必要がありました。 しかし、数台のサーバーを用意するだけでは負荷をかける側のサーバーの処理能力が足らず、満足な負荷をかけることができませんでした。また、環境構築を手作業で行うとたいへん時間がかかるため、台数確保の手間も問題になりました。そこで、100台規模のサーバーを新規に立ち上げ、それらのサーバーからJMeterを用いて負荷トラフィックを流し込む仕組みを、AWS + chef + fabricで自動化しました。
なお、サーバー上でJMeterを起動して負荷試験を実行する手順については、以下のブログの内容を参考にさせていただきました。 参考:http://dev.classmethod.jp/cloud/apache-jmeter-master-slave-100mil-req-min/
AWS
AWSのAPIを用いて世界中の各regionにec2 instanceを立ち上げます。実際は、日本への通信latencyの問題があるのでUS regionとAsia regionの中から選択しました。また費用面からmicro instanceを使用しました。chef
以下の設定をchefで行います。- Javaのインストール
- JMeterのインストール
- JMeterのテストシナリオファイルの配布
- JMeterの接続先情報ファイルの配布
# jmeter.properties
remote_hosts=server1:1099,server2:1099,server3:1099,......
こちらを手で編集するのは辛いのでAPIから取得した情報を元にファイルを生成するツールを用意し、chefのfileとして管理します。
fabric
fabric経由でjmeterを起動し、テストを行います。上記のような環境を準備することで、たとえば100台のサーバーを用いて1台あたり100スレッドで負荷をかけた場合、対象システムに同時接続数10,000といった負荷をかける事も容易にできるようになりました。またシナリオに不備があって手直しが必要な際も、設定の再配布〜再実行が非常に短いサイクルで行えるようになりました。 こちらの環境整備のお陰で、リリースの前に見つけるべき課題の多くを潰すことができ、非常に有益でした。
柔軟な環境構成の変更
弊社はAWS以外にも、国内のクラウドサービスについても併用しています。理由としては価格面であったり、サーバー等々のスペック面での優位性であったりします。 一例として、ある機能を担当していたサーバーをAWSから国内のクラウドサービスに移し替えました。転送量の節約や、SSDストレージが使える小規模なサーバー群を使用したかった事が目的です。サービスが異なると選択可能なOSのdistributionが異なるケースがありますが、chefのrecipeやattributeなどではOS環境ごとに挙動を変える事ができるため、chefの定義でOSの差を吸収することができます。 たとえばrecipeの振る舞いをOSごとに変える場合は以下のような記述になります。
case node['platform']
when "ubuntu"
puts "I am ubuntu."
when "centos"
puts "I am centos."
when "amazon"
puts "I am amazon."
end
その他、サーバーのCPUコア数などの取得もできるため、たとえばWebサーバーのworker数などを環境のスペックにあわせて設定することもできます。以下は、”worker_rlimit_nofile”という値を「CPUのコア数 × worker_connections数」として動的に設定する例です。
default['worker_processes'] = node['cpu'] && node['cpu']['total'] ? node['cpu']['total'] : 1
default['worker_connections'] = 1024
default['worker_rlimit_nofile'] = default['worker_connections'] * default['worker_processes']
今後について
現状は基礎的な準備が整った段階でまだまだ足りないところも多いため、これからもサービスの成長に合わせて、今回書かせていただいた構成管理についてもより最適な環境にしていきたいと思います。直近で最も課題になっているのは、構築したサーバー環境の設定や構成の妥当性に対する検証が不足している、という点です。この点はserverspecを使用したり、JenkinsなどのCIツールにて定期的にchefの設定ファイルの検証を行ったり、という形で対応をしていきたいと思っています。
また、社内で独自に作成したrecipeのメンテナンスも課題です。どうしても時間が経つと陳腐化したり、ドキュメント不足に起因して「どうしてこんな記述になってるんだろう…」というノウハウの喪失が起こります。 こちらについては、たとえば汎用的なcookbookについてはopscodeのサイトに公開する、などのアプローチも取って行きたいと思います。公開に足る品質にしようとすればドキュメントも整備する気持ちが生まれますし、有益なものであればコミュニティに対する還元もできます。
まとめ
以上、長々と、弊社におけるchefならびにfabricを用いたクラウドサービスの管理について書かせていただきました。chefやfabricなどのようなツールを駆使し、より作業を楽に、正確に、大規模に行えるようにし、今までそれらの作業に割かれていた時間を有効活用し、より本質的な価値を創造することに力を入れていく、そんな環境整備が大事だなと感じています。
我々はまだ小さな組織ですが、様々な技術を駆使してユーザーの皆様によい体験を届けられたらと思っています。今後ともSmartNewsをよろしくお願いいたします。
P.S. 株式会社ゴクロでは、SmartNewsの成長を加速してくれるエンジニアを募集しております。興味の有る方は是非お会いしましょう!