

ゴクロの大平です。ごくろうさまです。
Redisは高速で、かつデータの永続化や、複数のデータ型によるストア(list,set,sorted set等)も対応しており、機能的が豊富ということから愛用者の多いKVS実装の一つだと思います。 特に私のようなアプリケーションエンジニアの人間にとってはデータ型のバリエーションの豊富さが便利さを感じる部分で、たとえばlistを用いてタイムライン的な情報や履歴情報の管理、sorted setを用いてランキング情報の管理、などのようにアプリケーションの需要の多くにRedisが対応することができます。
これらの情報を登録する際のフローとしては自作のアプリケーションから直接、というケースが多いと思いますが、せっかくFluentdのような便利なlog collector実装があるので、FluentdとRedisを組み合わせる事でカジュアルに情報の蓄積を行いたい……というのが本記事執筆の背景です。
なお、本記事のタイトルは、からあげ方面で大変著名なささたつさん(@sasata299)のスライドにインスパイアされております。 Redisを使ったランキング機能の実装
Fluentdを用いたRedisへのデータ保存
Redisへデータを登録するFluentdのpluginは、かなり早いタイミングから存在しているようです。 https://github.com/yuki24/fluent-plugin-redisただし、こちらは流れてきたデータをひたすらhmsetで登録する、という形になっているようで、データの蓄積を行うというユースケースでは有効ですが集計系の処理には対応しきれていないようです。
あらためて、今回、私が行いたいと思っている処理のユースケースを整理すると以下です。
- 直近の履歴データ保存
- 特定の値をkeyとして、順序付きでkeyごとにvalueを保存
- listで保存(score 無し、重複許可)
- sorted setで保存(score 有り、重複不許可)
- 特定の値をkeyとして、順序付きでkeyごとにvalueを保存
- ランキングデータの保存
- 特定の値をkeyとして、score付きでvalueを保存
- sorted setで保存
- 特定の値をkeyとして、score付きでvalueを保存
履歴としてlistに登録する場合、以下のようにvalueに重複を許し、lpush / rpushによって挿入位置は異なりますが基本的にはデータは登録順に蓄積されていきます。
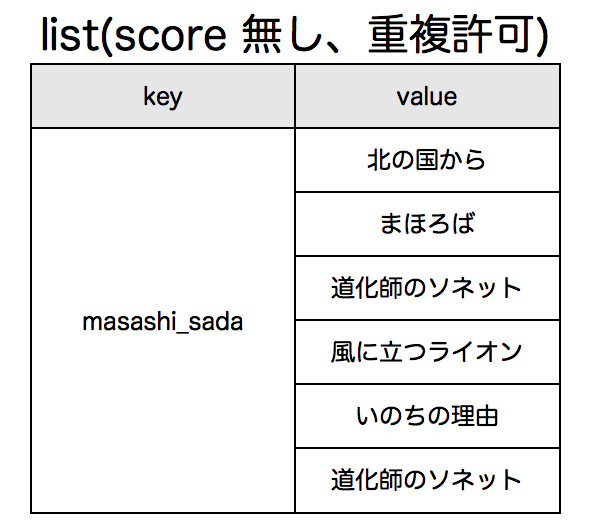
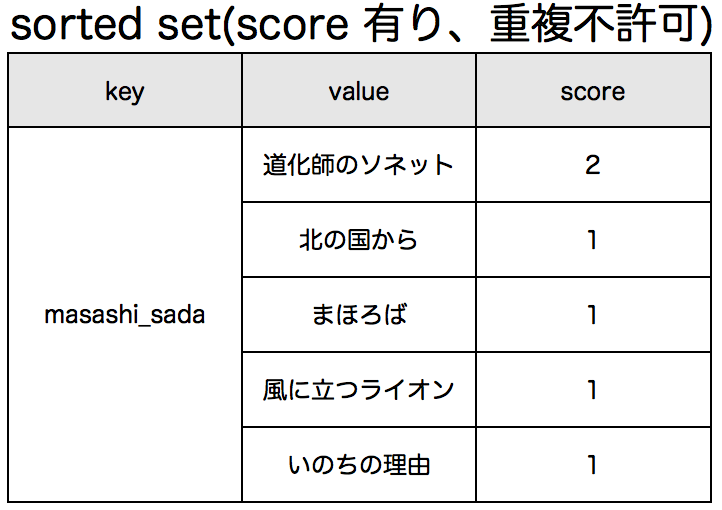
setやsorted set(zset)に登録する場合は、valueについては基本的に重複は許可されず、逆の言い方をすると一意性が保証されます。sorted setの場合はscoreの値によって取得時にsort済みの値が返却されます。scoreにたとえば最終処理時刻のunixtimeを設定すると時系列な履歴情報管理に使えますし、何かしらのランキング値を設定するとランキング情報の管理に使えます。
Fluentdの話に戻ると、上述のデータ構造に基づいたデータ蓄積に対応している既存pluginは私が知る限り存在していなかったので、今回作成してみました。
fluent-plugin-redisstore
https://github.com/moaikids/fluent-plugin-redisstore先のユースケースを実現するために作成したpluginです。コアな実装は先述のredis pluginの実装の大部分を踏襲しています。 できる事としては、箇条書きで書くと以下。
- 保存先のデータ型を複数から選択可能(string / list / set / zset)
- Redisへの保存対象となるkey / value / scoreの値を設定で指定可能
- key : prefixならびにsuffixの固定値 + 指定したkeyに含まれるvalue(prefix + (key) + suffix)
- value : 指定したkeyに含まれるvalue。数値でも、文字列でも可
- score : 指定したkeyに含まれるvalue。数値のみ。保存先がsorted setの際のみ有効
- list , zsetについて、特定のkeyに保存するデータ件数の上限を指定可能
- keyのexpireを設定可能
- zsetについて、各valueのexpireを設定可能(scoreにunixtimeを指定した場合のみ有効)
事例:ユーザーごとの閲覧履歴
ここでは、nginxのaccess logを元に、あるユーザーのページ閲覧履歴の管理を行う、とします。 nginxのログはltsv形式で出力され、ユーザーごとの一意IDのロギングと、アクセス時間のunixtimeをロギングする拡張がされていると仮定します。ログの出力例は以下。time:18/Sep/2013:16:52:46 +0900 uid:49726 uri:/musician/masashisada/ method:GET status:200 timestamp:1379490766
time:18/Sep/2013:16:52:46 +0900 uid:58374 uri:/musician/kyarypamyupamyu/ method:GET status:200 timestamp:1379490766
time:18/Sep/2013:16:52:47 +0900 uid:49726 uri:/musician/masashisada/ method:GET status:200 timestamp:1379490767
time:18/Sep/2013:16:52:48 +0900 uid:49726 uri:/musician/masashisada/ method:GET status:200 timestamp:1379490768
time:18/Sep/2013:16:52:52 +0900 uid:58374 uri:/musician/john-ken-nuzzo/ method:GET status:200 timestamp:1379490772
time:18/Sep/2013:16:52:53 +0900 uid:49726 uri:/musician/masashisada/ method:GET status:200 timestamp:1379490773
time:18/Sep/2013:16:52:53 +0900 uid:49726 uri:/musician/masashisada/ method:GET status:200 timestamp:1379490773
time:18/Sep/2013:16:52:54 +0900 uid:49726 uri:/musician/masashisada/ method:GET status:200 timestamp:1379490774
こちらのログを、Fluentdのin_tailで読み込み、先述のredisstoreでRedisに保存します。 まずはlist形式で保存する例です。
<source>
type tail
tag nginx.access
format ltsv
path /var/log/nginx/access.log
pos_file /var/log/fluentd/nginx_access.log.pos
</source>
<match nginx.access>
type redisstore
host localhost
port 6379
key_suffix _history
store_type list
key_name uid
value_name uri
value_length 3
</match>
- 保存形式:list
- key:(uid)_history
- value : (uri)
- 各listのvalueの最大長:3

続いて、sorted setに保存するケースです。
<match nginx.access>
(snip.)
key_suffix _history
store_type zest
key_name uid
value_name uri
score_name timestamp
value_length 3
</match>
- 保存形式:zset
- key:(uid)_history
- value : (uri)
- score : (timestamp)
- 各setのvalueの最大長:3

このような形で、Fluentd+Redisの組み合わせで手軽に履歴情報の保存を行う事ができます。
ランキングデータの集計
履歴情報の保存は手軽ですが、ランキング情報を保存する場合は事前に集計処理を行う必要があり、これをFluentdで処理しようとすると少し事情が複雑になります。 in_execなどを使用して、外部スクリプトを呼び出しその中で集計処理を行う、というのも一つの手ですが、処理コストが高いためデータサイズが大きくなるとスケールしなくなります。 また、たとえばページの閲覧ランキングを算出するとした場合、ページが数多く存在すると集計のために多くのメモリ空間を使うことになります。Fluentdで何かしらの集計処理を行おうとした場合、集計処理の速度も確保し、かつできる限りリソースを節約したりと、現実的な方法で集計処理を行う必要があります。
fluent-plugin-lossycount
https://github.com/moaikids/fluent-plugin-lossycount ということで、限られたリソースで集計処理を行うロジックとして、lossy countingに基づいた集計処理ができるFluentd pluginを作ってみました。 lossy counting algorithmは非常に一般的なアルゴリズムで、多くの参考になるページが存在いたしますので本記事では詳細は割愛します。[参考]lossy countingによる集計の特性としては、gamma値とepsilon値を適切に設定することでデータ総数Nに応じ下記のようなデータを必ず出力できる事を保証している事です。また、『オンラインアルゴリズムとストリームアルゴリズム』という書籍の章6.2においてもストリーム処理における近似アルゴリズムのひとつとして紹介されています。
- 超大規模テキストにおけるN-gram統計
- http://d.hatena.ne.jp/jetbead/20111014/1318547950
- 大規模データで単語の数を数える
- http://d.hatena.ne.jp/ny23/20101108/p1
- 誤り許容カウント法(lossy count method)のサンプルプログラム
- http://chalow.net/2010-05-12-1.html

- 出現頻度が “gamma × N” 以上のデータはすべて出力される。
- 出現頻度が “(gamma - epsilon) × N” 未満であるデータは出力されない。
- 出力される頻度は近似値で、誤差は必ず “(正確な頻度) - (epsilon × N)” の間に収まる。
- gamma = 0.005
- epsilon = 0.004
- N = 1000000
- 出現頻度が “0.005 × 1000000 = 5000” 以上のデータは必ず集計が行われる
- 出現頻度が”(0.005 - 0.004) × 1000000 = 1000” 以下のデータは集計が行われない。
- 近似値となる集計結果の真の値との誤差は”0.004 × 1000000 = 1000”の間に収まる。
端的に言うと、gammaやepsilonの値を調整することで、集計結果の誤差や、欠落させる情報/集計する情報の閾値の設定を一定の条件下にコントロールして行う事ができる、という感じになります。 ある程度の誤差が許容されるようなtop-Nの情報抽出であれば、こういったアルゴリズムの使用はリソースの節約につながるため、小規模の計算リソースでも集計処理が行えるという利点があります。 逆に欠点としては、あくまで近似アルゴリズムであるという事と、出現するデータがいわゆるzipf’s lawに則っていない場合…たとえばすべてのデータが同一頻度で出現する場合…には有効では無いことが挙げられます。
事例:fluent-plugin-lossycountのテストケース
動作例としてfluent-plugin-lossycountのテストケースを例に挙げます。git clone https://github.com/moaikids/fluent-plugin-lossycount.git
cd fluent-plugin-lossycount
rake test
上記のようにテストを実行するといくつかのテストケースが実行されますが、そのうちの一つとして700000件のランダム生成したデータの集計処理が実行されます。結果の統計情報は以下のような形式で出力されます。
{"num"=>700000, "max_size"=>192, "current_size"=>139, "reduced_size"=>35, "gamma"=>0.005, "epsilon"=>0.0045, "n_x_gamma"=>3500.0, "n_x_gamma-epsilon"=>350.0000000000003}
上記は、恐らく集計対象のデータが200件近くあった中、lossy countingのアルゴリズムにより上位35件のデータについて集計が行われた、という事を表しています。
事例:ページの閲覧ランキング
閲覧履歴の時と同様にaccess logのデータを元にして、ページごとのランキング情報を集計し出力することを考えてみます。<source>
type tail
tag nginx.access
format ltsv
path /var/log/nginx/access.log
pos_file /var/log/fluentd/nginx_access.log.pos
</source>
<match nginx.access>
type lossycount
time_windows 3600
gamma 0.005
epsilon 0.004
output_tag ranking.access
key_name uri
output_key_name uri
output_timestamp_name timestamp
output_value_name count
</match>
<match ranking.access>
type redisstore
host localhost
port 6379
key_suffix _ranking
store_type zset
key_suffix _ranking
key_name timestamp
value_name uri
score_name count
value_length 3
</match>
[lossycount]
- time_windows:3600 seconds (1時間に1回集計処理をする)
- gamme:0.005
- epsilon:0.004
- 集計する値:uri
- 保存形式:zset
- key:(timestamp)_ranking
- value : (uri)
- score : (count)
- 各setのvalueの最大長:3
20130918T170000+0900 ranking.access {"uri":"/musician/masashisada/","timestamp":1379491200,"count":3316}
20130918T170000+0900 ranking.access {"uri":"/musician/kyarypamyupamyu/","timestamp":1379491200,"count":2984}
20130918T170000+0900 ranking.access {"uri":"/musician/john-ken-nuzzo/","timestamp":1379491200,"count":2357}
あとはこのデータをどのように扱うか、という事になりますが、Redisにランキング情報として保存する場合は上記の設定のようにランキング項目をvalue、ランキングの重みをscore、となるようなsoreted setとして保存するようにしてあげればOKです。 一応結果を図示すると、以下のような形になります。

まとめにかえて
以上、FluentdとRedisを組み合わせてカジュアルにランキングの集計や、履歴情報の保存を行う方法について紹介いたしました。何かしらの集計を行いたい場合、バッチ処理やElastic MapReduceなどを用いる方法も当然ありますしデータの正確性を担保するためには全データを対象とした集計処理が必要になりますが、即時性が求められるデータをストリーム処理的に扱いたい場合は本記事のようなアプローチもそこそこ有効ではないかと考えています。
紹介した2つのFluentd pluginについてはすでに数ヶ月の間無事に稼働しているため基本的な部分は問題無いと思いますが、機能の追加やパフォーマンス面の調整、あととにかくドキュメントをまともに書いてないためその辺の拡充が必要と考えています。この辺は時間の許す限り、という感じで粛々と行っていきたいと思います。
なお、先日、さだまさしさんのベストアルバム『天晴』が発売されましたが、こちらはCD三枚組で、ファン投票(「あなたが選ぶ さだまさし国民投票」)のランキング上位の楽曲39曲が収録されています。 http://www.u-canent.jp/masashi/all_time_best/#ranking こちらのランキング集計には、恐らくFluentdとRedisは使われてないと思いますし、基本的に(というか当然のことながら)本記事とは無関係です。はい、余談でした……。