ゴクロの大平です。
私にとって一番大事で替えの効かないミュージシャンはさだまさしさんですが、私にとってクラウドコンピューティングのサービスの中で一番大事で替えが効かないサービスはS3です。 多種多様なAPIを用いて柔軟にファイルの操作が出来る事や、”99.999999999%”と謳われている高い耐障害性、S3にあるデータをElastic MapReduceやRedshiftなどを用いて手軽にデータ解析を行える基盤が提供されていることなど、あまりに便利すぎてS3の代替となるサービスを探しだすのが難しい状態です。
もちろん多くのAWSユーザーが同じようにS3の便利さを享受していると思いますし、インターネット上でも多くのブログ等でその魅力が語られています。その中で本記事は既に存在する記事と似たような内容を書いてしまうかもしれませんが、弊社なりのS3の使い方についてご紹介したいと思います。
なお、S3は、”Simple Storage Service”の略称で、”Sadamasashi さん”の略称ではありませんので、くれぐれもお間違えの無きようご注意下さい。
SmartNewsで扱うログファイル
弊社の提供するSmartNewsはiPhoneやAndroid端末上で動作するネイティブアプリです。 情報の取得はインターネットを介してサーバーに接続して行いますが、情報取得後の操作については例えネットワーク接続が不安定な環境でも快適に操作をしていただくために多くの機能がオフラインでも操作可能になっています。システム管理者側の視点、データ解析者側の視点として、従来の多くのWebサービスのようにWebサーバーのログのみを解析対象にするとSmartNewsのようなアプリではユーザーの行動の多くがブラックボックスになってしまい、的確な改善施策を行う事が難しくなります。 この辺の事情は多くのネイティブアプリで同様と思いますが、弊社では大別して以下2種のログファイルを取得し保存をするようにしています。
- サーバーへのリクエストログ(サーバー内に蓄積)
- アプリケーション内での操作ログ(アプリ内に蓄積→定期的にサーバーに送信)
Fluentdを用いたS3へのログ保存

しかし今ではこの課題で頭を悩ませる事は少なくなり、Fluentdを用いる事で非常に手軽に、かつ安定してログの保存が行えるようになりました。 Fluentdは今や超人気OSSの一つですので今更説明は不要と思いますが、一応「はてなキーワード」に記載されている内容を以下に引用します。
メッセージングのコレクションサービス。フレームワークとして抽象化されており、各種プラグインを利用することで、様々なメッセージングを集約、伝搬することが出来る。FluentdにはS3を保存先としてデータを書き出すout_s3プラグインが存在しますので、こちらを用いる事でログ情報をS3に簡単に書き出す事ができます。
nginxログ(ltsv形式)→Fluentd→S3
一般的な例の一つとして、ltsv(Labeld Tab Separated Value)形式で保存されたnginxのアクセスログをFluentdに書き出す例について説明します。 ちなみにltsvは可読性が高いことや、ログ出力順にロバストで項目追加に神経を使わずにすむため、データサイズがそれほど肥大化しないログファイルについては弊社でもこのフォーマットを良く使用しています。構成図
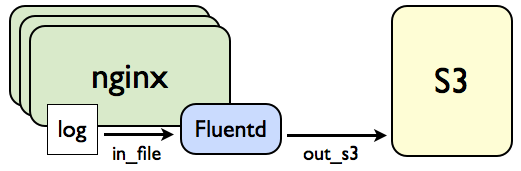
nginx
まず、nginxの設定ファイル中で、log_formatディレクティブを使用してltsvのフォーマットの則った出力定義を記載します。 基本的には「(label 1):(value 1)t(label 2):(value 2)t…(label n):(value n);」のように、labelとvalueのboundaryに”:“を、label:valueの対のboundaryにタブ文字’t’を指定して、データ構造を組み立てていきます。log_format ltsv 'time:$time_localt'
'msec:$msect'
(snip.)
'vhost:$host';
labelの名前は基本的には任意ですが、『WEB+DB Press』の74号の記事「LTSVでログ活用」にltsvを使用する際の「推奨ラベル一覧」が記載されていますので、こちら等を参考に名前付けをしていく事をお薦めします。
上記のようにログ出力定義を記載したら、access_logディレクティブを用いてログの保存先とログフォーマット(今回はltsv)を記載すればOKです。
access_log /var/log/nginx/access.log ltsv;
Fluentd
Fluentdではファイルから情報を読み込むin_tailプラグインを用いてログを取り込みます。Fluentdにはバージョン0.10.32より標準でltsvのログパーサーが存在しますので、「format ltsv」と記載すればltsv形式のログを取り込む事ができます。<source>
type tail
tag nginx.access
format ltsv
path /var/log/nginx/access.log
pos_file /var/log/fluentd/nginx_access.log.pos
</source>
出力はout_s3プラグインを用います。
<match nginx.access>
type s3
aws_key_id [aws_key]
aws_sec_key [secret_key]
s3_bucket [bucket_name]
s3_endpoint [region_name].amazonaws.com
s3_object_key_format %{path}%{time_slice}_%{index}_%{hostname}.%{file_extension}
path logs/
buffer_path /var/log/fluentd/s3
time_slice_format %Y-%m-%d/%H
time_slice_wait 10m
</match>
使用しているAWSのkey_idやsecret_key情報、保存先のbucket情報などを設定していきます。 上記のように設定することで、指定したbucketにs3_object_key_formatで指定したフォーマットに従ってログファイルが保存されるようになります。
アプリケーションログ→Fluentd→S3
構成図
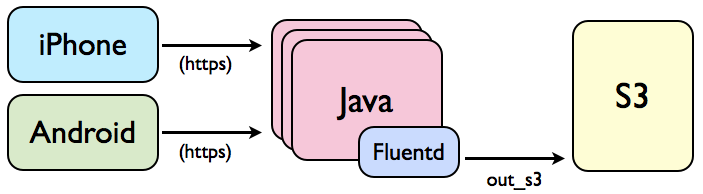
続いてアプリケーションログの例です。iPhoneならびにAndroid端末上で蓄積されていくログ情報を定期的にインターネットを介してJavaサーバーに送信し、その内容をさらにS3に保存する構成になっています。 JavaからFluentdへの送信は、Java用のFluent-logger実装を使用しています。Fluentdが受け取った内容をS3に書き出す件は先述のものと同様です。
イベントごとに保存先を切り替え
トラッキング対象としているユーザーの操作イベントは多種多様なため、送信されるログファイル中にイベントIDを埋め込むことで発生したイベントを管理しています。 解析用途で使用する場合、一つのファイルに複数のイベント情報が含まれている状態は好ましくなく、イベントごとにファイルの保存先を変えたくなります。
もちろん、ログファイル中の値によって保存先を切り替えることも、Fluentdを用いると簡単に行えます。ひとつの手法として、rewrite_tag_filterプラグインを使用してタグを書き換える、という方法をここでは紹介します。
たとえばFluentdに流れてくるデータが以下のようなフォーマットだったとします。
1970-01-01T00:00:00+09:00 log.ios {"event":"register"}
“event”に各種イベント名が含まれており、保存する際はタグ名とイベント名の組み合わせで保存先を変更したい、という場合は以下のように設定します。
<match log.**>
type rewrite_tag_filter
remove_tag_prefix log
rewriterule1 event (.*) hoge.$1
</match>
上記設定では、”event”の値に応じてタグを書き換える、という定義を記載しています。 上述のログファイルを例とすると
“log.pc” →”hoge.register”(rewriterule1)という流れで、”log.pc”というタグがrewrite_tag_filterを通過することで”hoge.register”という風に書き換えられます。
後は、以下のように、タグの名前に応じてS3の保存先を切り替えるようにしてあげれば、イベントごとにログの保存先を切り替える、という事が実現できます。
<match hoge.**>
type forest
subtype s3
<template>
aws_key_id [aws_key]
aws_sec_key [secret_key]
s3_bucket [bucket_name]
s3_endpoint [region_name].amazonaws.com
path logs/${tag}/
buffer_path /var/log/fluentd/${tag}
</template>
</match>
データの保存先(path ならびに buffer_path)にplace holderとして${tag}を指定しています。 このように設定しておくと、”hoge.**“にマッチするデータについてタグごとに logs/ 配下に保存されるようになります。
一点注意として、out_s3はfile typeのbufferを標準では使用するようになっており、いったんバッファしたデータを特定フォルダ(buffer_path)に保存します。そのため、pathの保存先をタグごとに振り分けるだけでなく、buffer_path の保存先についてもタグごとに振り分けて置かないと、同じbufferファイルに複数タグのデータが保存され、S3保存時にも同じファイルとして一緒くたに保存されてしまいます。 逆に言うとそこだけ気をつければ、簡単に保存先の振り分けが行えます。
S3の費用節約
S3は非常に便利ですがもちろんお金がかかるサービスのため、野放図にログを大量に貯めこむと予想外の出費が生まれることがあります。そのため、できる限り費用を節約する方法として、以下2つのテクニックについてご紹介します。S3のLifecycleの活用
S3には、特定のbucket内のデータに対して有効期限(Lifecycle)を設定することが可能です。Lifecycleを設定することで、有効期限に達したファイルを自動的にGlacierに保存したり、削除したり、といった事が可能です。Glacier
Glacierは2012年8月に公開された、ファイルを既存のS3の約1/10の低価格で保存できるサービスです。制約として、一度Glacierに保存したファイルの復元には数時間かかりますが、参照頻度の低いログファイルの長期保存には非常に向いています。Lifecycleの設定
LifecycleはAPI経由で設定を行う方法もありますが、視覚的に分かりやすいのでここではS3の管理コンソールを例に説明します。Lifecycleを設定したいS3のbucketを表示し、画面右上にある「Properties」ボタンを押下すると、各種設定項目が表示されます。その中に「Lifecycle」という項があるので、こちらの「Add Rule」というボタンを押下すると、以下の画面が表示されます。
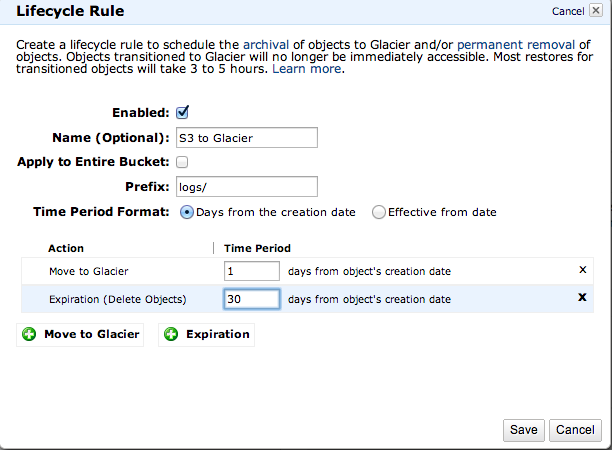
bucket内の「Prefix」で指定したパス条件に合致するファイルについて、定期的にアクションが実行されます。 追加できるアクションは以下2つです。アクションはいずれか1つの指定も、2つ組み合わせた指定も可能です。
- Move to Glacier : ファイルを作成しからTime Periodに指定した日数経過後、ファイルをGlacierに移動
- Expiration : ファイルを作成してからTime Periodに指定した日数経過後、ファイルをS3から削除
Reduced Redundancy(低冗長化ストレージ)の活用
Glacierは確かに安いですが復元に時間がかかるため、解析処理などで常に即時閲覧が必要となるようなデータに対しては不向きです。 それでもできるだけ安く保存したい、という用途向けにReduced Redundancyという保存オプションが用意されています。冒頭に述べたようにS3はStandardモードで99.999999999%の耐障害性を保証すると謳われていますが、Reduced Redundancyは99.99%に信頼性が落ちる代わりにStandardモードの8割程度の金額で使用できます。信頼性が必要なデータには不向きですが、たとえ万が一データロストしても許容されるようなデータについてはReduced Redundancyで保存した方が価格的にお得になります。
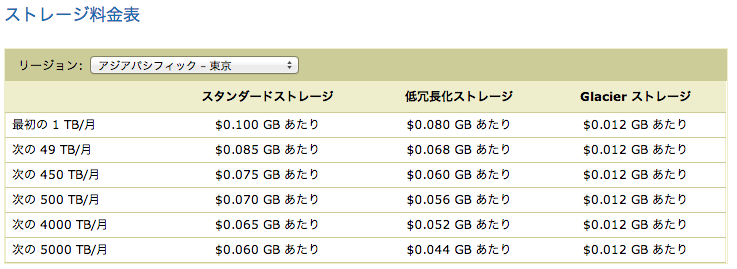
なお、Glacierも含めて、S3の価格表のページから引用すると、以下のような価格設定になっています。(2013年8月20日 現在)
保存モードはS3管理コンソールからでも行えますが、できればFluentdからS3に保存する際に自動的にモードを指定したいところです。
現在のところ標準のout_s3プラグインではReduced Redundancyモードでの書き込みに対応していないようなので、弊社ではforkし自前で拡張したプラグインを使用しています。 変更点としては、以下のようにS3に書き込む際にオプションを追加する、だけになります。
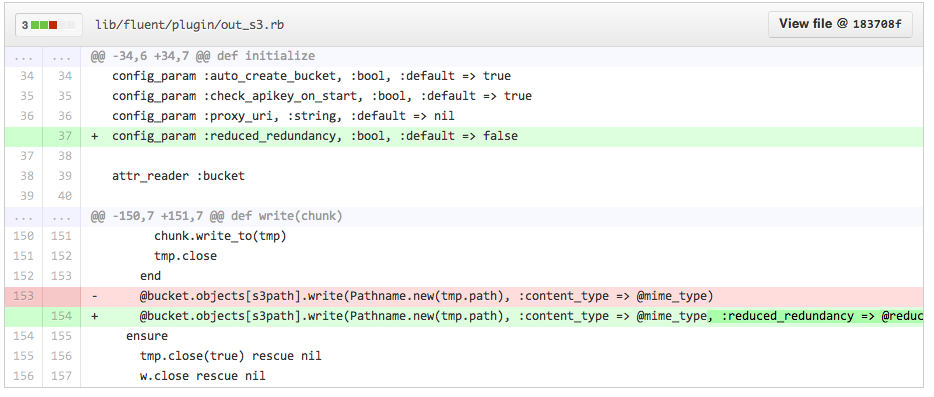
システム設計としてはFluentdを用いてS3にひたすらログを書き込む事に集中し、Fluentd Pluginのオプションの設定や、S3のLifecycleの設定によって適切なファイルモードの管理や保存期間の管理をする。 そんな感じで、効率的なS3でのログ管理ができるのでは無いかと思います。
ログ解析の話、もしくはFluentdの話 (注:今回は割愛)
ログをS3に蓄積する主目的は、ログを解析することで様々な情報を取得することにあり、流れとしては蓄積したログをAWSが提供しているElastic MapReduceなどを組み合わせてデータ解析を行う、という流れになります。 しかし今回は前段のログを蓄積する話に文量を割きすぎてしまったため、この辺の話は次回以降に紹介させていただければと思います。。また、Fluentdについては、上述のようなS3へのログ出力以外にも非常に様々な用途で使用しており、独自のプラグインを作成して運用なども行っているため、こちらについてもいずれ当ブログなどでご紹介できればと思っています。
まとめ
Fluentdを用いたS3へのログ保存について、お話をさせていただきました。 色々な方とお話していても「Fluentd+S3はクラウド時代のログ管理のスタンダード」という意見をよく耳にしますし、弊社でもその利便性を余すところ無く享受させていただいている、という感じです。今回は非常に一般的な内容になりましたが、一回では書ききれない事が多いため、今後の記事でデータ解析やFluentdについてもう少し踏み込んだお話ができれば良いな、と思っております。
なお宣伝ですが、弊社ではデータサイエンティストの方以外にも、様々なバックグラウンドを持つエンジニアの方々を鋭意募集中です。ゴクロがどんな会社か知りたい、SmartNewsの技術について話を聞きたい、寿司串カツ食べたい、動機は何でも構いませんので、興味のある方がおられたら是非弊社まで遊びに来てください。
採用情報
参考文献・URL
- LTSVフォーマットなログを fluentd + GrowthForecast で料理
- http://d.hatena.ne.jp/naoya/20130205/1360088927
- nginxでltsv形式のaccess.logを出力する
- http://itsneatlife.blogspot.jp/2013/06/nginxltsvaccesslog.html
- 自在にタグを書き換える fluent-plugin-rewrite-tag-filter でログ解析が捗るお話 #fluentd
- http://d.hatena.ne.jp/yoshi-ken/20120701/1341137269
- fluent-plugin-forest released!
- http://d.hatena.ne.jp/tagomoris/20120410/1334040981
- Fluentd + out_s3 でタグごとに出力先フォルダを変更する
- http://itsneatlife.blogspot.jp/2013/06/fluentd-outs3.html
- Object Lifecycle Management
- http://docs.aws.amazon.com/AmazonS3/latest/dev/object-lifecycle-mgmt.html
- 【AWS発表】Amazon S3がさらに便利に! データをAmazon Glacierに自動アーカイブできるオプションが追加!
- http://aws.typepad.com/aws_japan/2012/11/archiving-amazon-s3-data-to-amazon-glacier.html
- s3 の Reduced Redundancy Storage に書き込む
- http://itsneatlife.blogspot.jp/2013/06/s3-reduced-redundancy-storage.html
- #smartnews_sushi
- https://twitter.com/repeatedly/status/367524897875976192