みなさまはじめまして、スマートニュースの井口 (いのくち; @kainoque) です。
SmartNews におけるコンテンツ配信システムの開発を全般的に担当しています。
この記事では、SmartNews のプッシュ通知の遅延という障害発生から、それを修正し、最終的にはその配信速度を 2 倍以上にまでスピードアップさせた方法と、それを実現するために重要だった考えについてお伝えしたいと思います。
もくじ
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!
SmartNews のプッシュ配信通知が倍速になるまで
SmartNews のプッシュ通知配信とその遅延の影響
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!
SmartNews は、ニュースをはじめとしたさまざまなコンテンツを配信するアプリです。
SmartNews のプッシュ通知では、そのときそのときの重要なコンテンツを定期的に配信しています。
また、大事件や地震などの緊急度が高い情報をふくむコンテンツを、号外通知というかたちで配信することもあります。
ユーザのみなさまは、プッシュ通知の受け取りをきっかけに SmartNews をひらいていただけることがとても多いです。ユーザのみなさまが SmartNews で良質なコンテンツをいち早く知ることができるようにプッシュ通知をお届けすることは、われわれの大きな使命の一つとなっています。一方で、その配信の遅延は非常に大きな問題になります。
今回の遅延のきっかけ
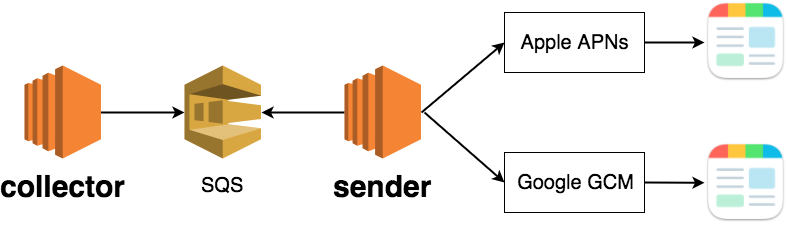
プッシュ通知配信システム
上記のとおり、SmartNews のプッシュ通知配信システムは大まかに以下の二つの機能から構成されています。
- ユーザごとに配信対象のコンテンツを決める
collector - 配信対象のコンテンツをそれぞれのユーザに送る
sender
collector と sender が、AWS の分散キューイングサービスである SQS を通じてユーザごとの配信対象のコンテンツを非同期にやりとりし、一度に大量のプッシュ通知配信を実現しています。
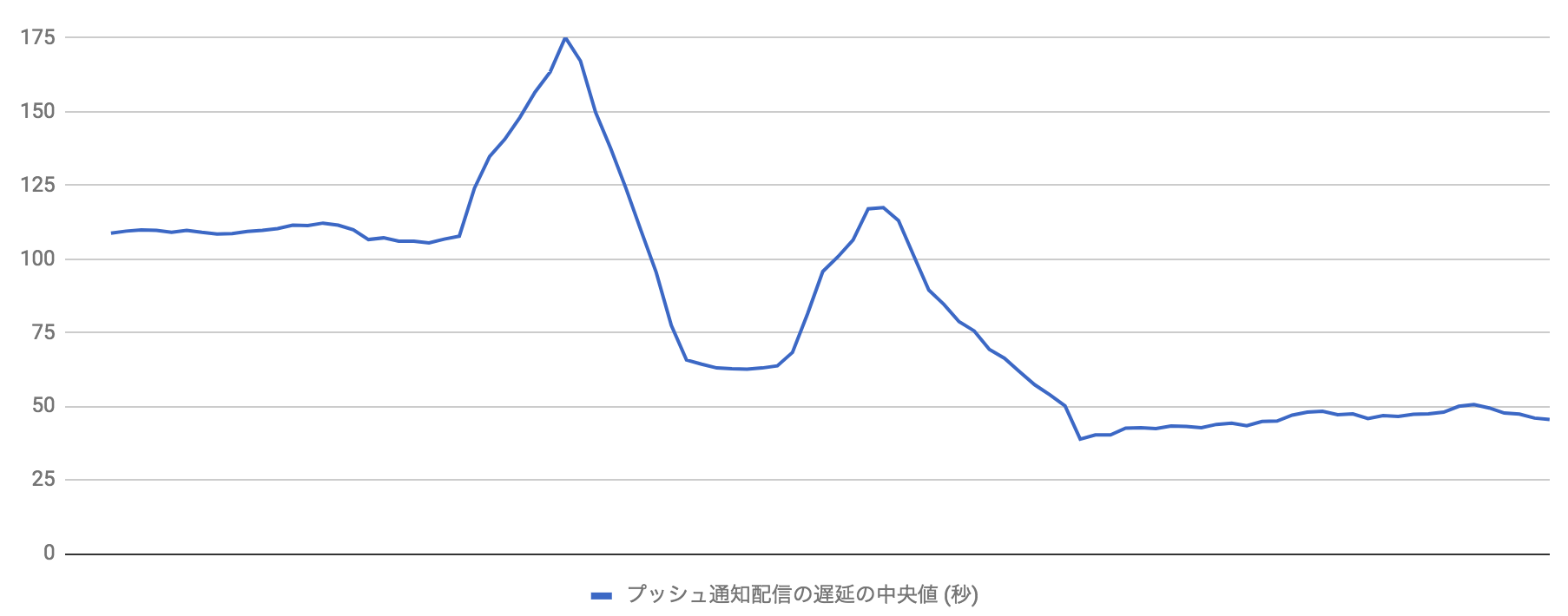
遅延のきっかけは、プッシュ通知配信システムの高機能化にともなうものでした。 その結果として、collector と sender 間でやりとりされるデータ量が増大し、配信遅延につながっていました。
発生した遅延
次の章では、これらの遅延にどのように対応し、その結果どのように配信速度を 2 倍にまでスピードアップさせたかについてお話させていただきます。
なお、これ以降登場する擬似コードはすべて GitHub 上でも確認可能 です。
対応 1: iOS への配信が遅れている?
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!
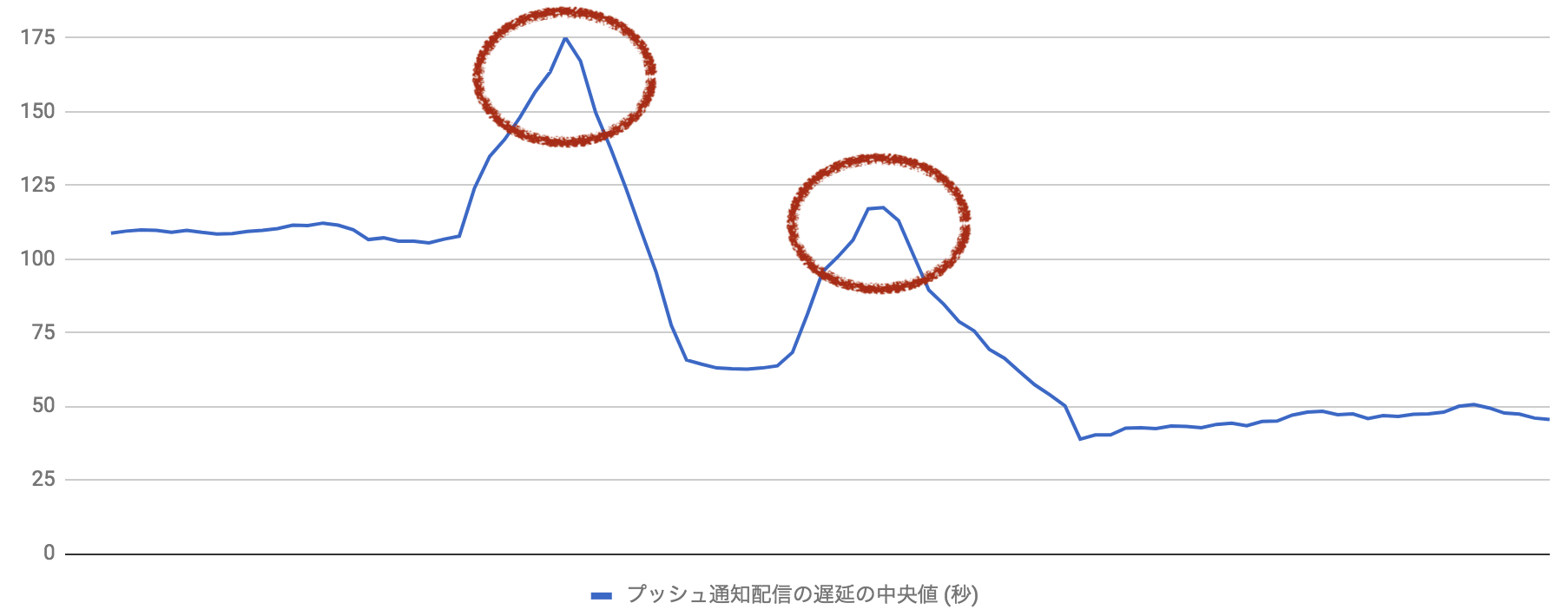
最初の配信遅延は、高機能なプッシュ通知の配信を iOS ユーザの多くに広げていくなかで発生しました。 それに先立つ Android ユーザへの展開では問題がありませんでした。以下の通り iOS 展開後に遅延が拡大していることがわかります。
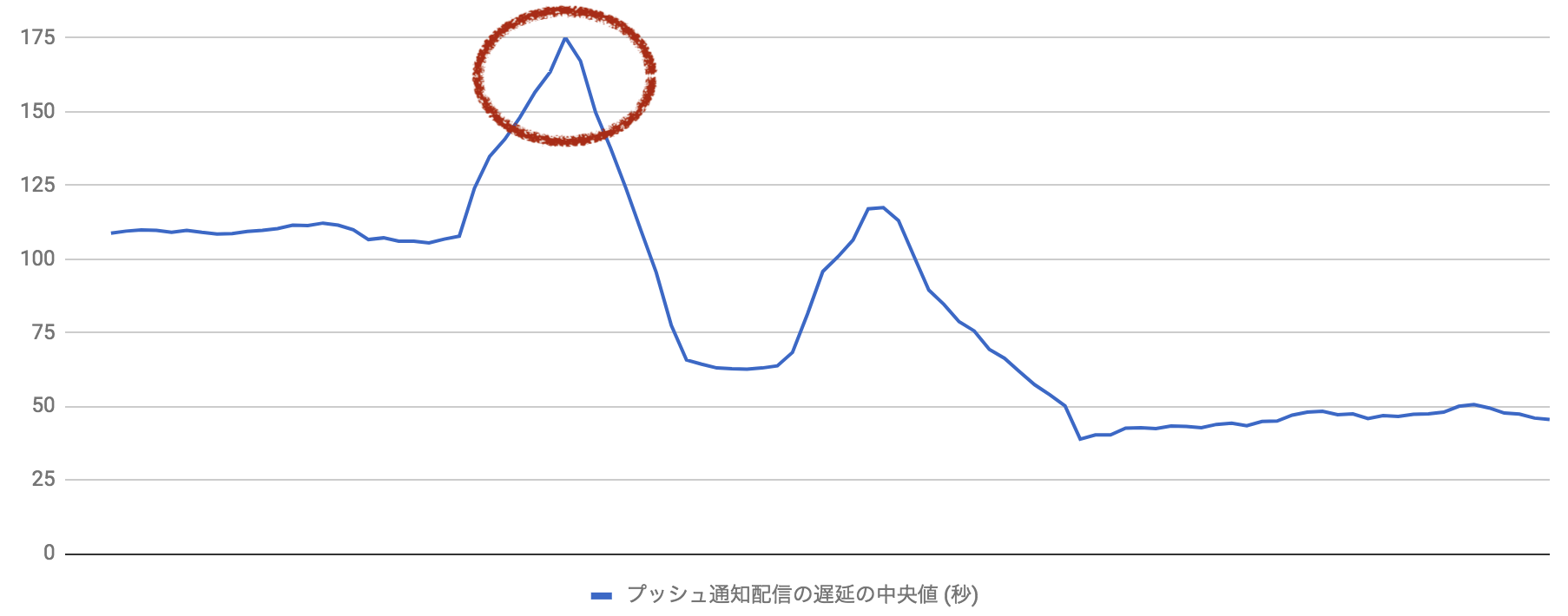
最初の遅延
ここから、「iOS 用の配信処理、なかでも特に、SQS のデータの量に依存する問題がありそうだ。」と仮説をたてて検証を開始しました。
検証
sender 内部の処理は、以下のようなシーケンスで表すことができます。
SQS からのメッセージ取得を担当する処理と、メッセージから複数の配信情報を取得し実際に配信を行う処理です。
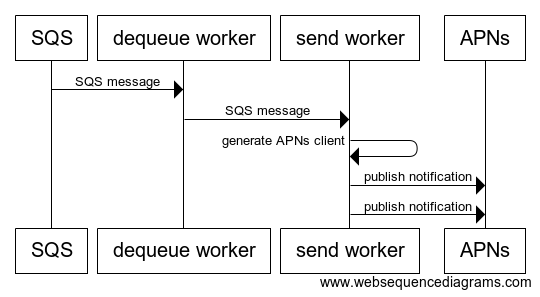
プッシュ通知配信処理のシーケンス
さきの仮説を検証するために、SQS のメッセージの量を変化させ、それに含まれるユーザごとの配信情報一つ一つの処理終了までの時間 (SQS から dequeue し APNs への配信が終了するまで) を計測しました。
以下は、擬似コードにより複数回検証を行った際の数値です。実際の数値とはことなりますが、おなじ傾向を持ちます。
| SQS のメッセージの量 | 平均値 | 中央値 | 99 パーセンタイル値 | 最大値 | 最小値 |
|---|---|---|---|---|---|
| 100 | 1,886 | 1,854 | 2,388 | 4,882 | 1,486 |
| 500 | 5,084 | 5,481 | 9,379 | 10,252 | 1,805 |
| 1,000 | 8,625 | 8,622 | 16,464 | 20,792 | 1,747 |
| 2,000 | 16,000 | 16,257 | 31,662 | 33,770 | 1,835 |
- 試行回数
100 - SQS メッセージ内のユーザ数
10 - 単位
ミリ秒(小数点以下切り捨て) - 擬似コードでの再現なので、実際の数値とはことなります
このように、SQS のメッセージの量が増えるに従って、各通知配信処理の遅延の最大値の値が増加していくことがわかりました。一方で、中央値や 99 パーセンタイル値についてはメッセージの量の影響が少ないこともわかりました。
ここから、 ある配信処理の遅延が悪化したときに、全体の処理も引きずられて遅くなっているのではないか という観点にしぼり、実際のコードを見ていきました。すると、次のような問題が浮かび上がってきました。
問題: 一つの処理性能の悪化が全体に影響することがあった
コードを見ていくと、SQS メッセージ内に含まれている各ユーザへの通知配信を parallelStream を用いて処理していることが判明しました。
以下がその処理の擬似コードによる再現です。
SQS のメッセージが dequeue されるたびに sendAsync が呼び出されます。sendWorker は、SQS のメッセージを並列で処理するための thread pool (ExecutorService) です。 sendWorker のなかで、メッセージに含まれるユーザごとの配信情報 (UserData) が、 parallelStream によって並列に配信されます。
public void sendAsync(SQSMessage sqsMessage) {
sendWorker.submit(() -> {
ApnsClient client = ApnsUtils.generateApnsClient();
if (client == null) {
return;
}
List<UserData> dataList = sqsMessage.getDataList();
dataList.parallelStream().forEach(data -> doSend(client, data));
try {
client.close().await(1, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
// Error handling
}
});
}parallelStream を使用する際には、よく知られたポイントも含めて以下に注意する必要があります。
- 使用する thread pool を明示的に指定しない場合、システム共通の
ForkJoinPoolであるForkJoinPool.commonが使用される (ForkJoinTask#fork) forEach処理呼び出しの際に、各タスク (ここではdoSend) が pool 内のどの worker で処理されるかが決定される (ForEachOps.ForEachTask#compute)- 共通の pool が詰まった場合、処理が caller thread で行われる (
ForkJoinPool#helpComplete)
このような特性から、parallelStream は予想される処理速度が均一であり、分割併合処理が可能なデータを処理 するのに向いており、残念ながら外部サービスとの通信を伴う今回のユースケースには適さない実装となります。
parallelStream の使用が今回のケースに与えた影響は以下のようになります。
- 配信処理 (
doSend) がシステム共通の pool で実行される - ある
doSendの処理が遅かった場合、おなじ worker で処理予定のdoSendは待たされることになる - 共通の pool でさばききれなかった処理は
sendWorker内 (caller thread) で実行される - 結果として、SQS メッセージを受け付ける
sendWorkerが詰まることになる
SQS を流れるデータが増加したことで、sendAsync の呼び出し回数も多くなっていました。そのため、上記が発生する頻度が高くなり遅延につながっていました。
本件とはことなりますが、弊社の他システムでも parallelStream に関係する問題があり、ForkJoinPool の内部構造に関する知見が共有されていました。そのため、今回のケースでも比較的速く問題の一つに気づくことができました。
参考: Javaのforkjoinとparallel()について (たむたむの日記)
問題: 不必要なブロック処理が存在する
上記のとおり、一つ一つの通知の配信処理である doSend の処理が悪化してしまうと、全体の足を引っ張りかねない作りとなっていました。
実際に、doSend のなかでは APNs との通信を行っています。この処理はネットワークや Apple のサーバの事情により時間がかかり、全体の処理に影響する可能性がありました。
APNs への通信は pushy という OSS のライブラリを利用しています。
このライブラリは、OSS の event-driven な非同期 IO 処理フレームワークである Netty ベースの実装となっています。
コードを見ていくと、配信処理を行った結果を受け取りそれに応じた後処理をする箇所で、結果を表す io.netty.util.concurrent.Future オブジェクトを、caller thread をブロックしながら取得している箇所がありました。以下がその処理の擬似コードです。
private void doSend(ApnsClient client, UserData data) {
String pushToken = String.format("dummy_for_%s", data);
String payload = String.format("test for %s", data);
String collapseKey = String.format("collapse_key_for_%s", data);
// Start sending a notification to APNs
Future<PushNotificationResponse<SimpleApnsPushNotification>> future = client.sendNotification(
new SimpleApnsPushNotification(
pushToken,
ApnsUtils.APNS_TOPIC,
payload,
null,
DeliveryPriority.IMMEDIATE,
collapseKey
)
);
try {
// Get the result from APNs
PushNotificationResponse<SimpleApnsPushNotification> response = future.get(
ApnsUtils.APNS_TIMEOUT,
TimeUnit.SECONDS
);
// Do post process with response
} catch (Exception e) {
// Do error handling
}
}このブロック処理により、APNs との通信に時間がかかった場合に前述の問題が発生してしまうことがわかりました。
対応と結果
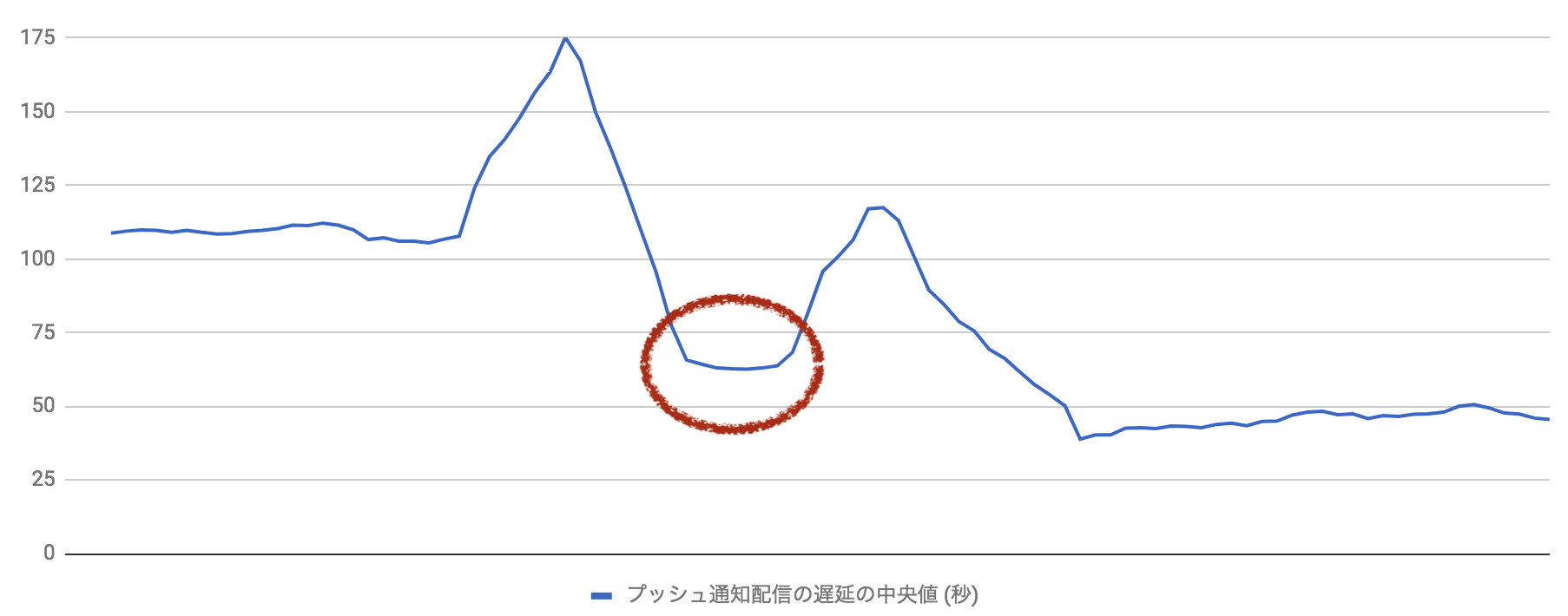
最初の遅延の解消
これら二つの問題を次のように修正し、遅延が解消されました。
parallelStreamではなく、ExecutorServiceを利用して並列処理を行うようにしたことで、特定の重い処理に全体が引きずられることがなくなりました。- 非同期の通知配信処理の結果待ち合わせは Netty の event loop に任せてしまうことで効率よい処理が可能になり、
doSendの実行自体が詰まってしまうことがなくなりました。pushy の Wiki にも、ベストプラクティスとして記載があります。
これらの修正適用後の擬似コードは以下のようになります。
public void sendAsync(SQSMessage sqsMessage) {
ApnsClient client = ApnsUtils.generateApnsClient();
if (client == null) {
return;
}
List<UserData> dataList = sqsMessage.getDataList();
CountDownLatch latchForClose = new CountDownLatch(dataList.size());
dataList.forEach(data -> sendWorker.submit(() -> doSend(client, data, latchForClose)));
// close client after all the messages are sent.
closeWorker.submit(() -> {
try {
latchForClose.await(3, TimeUnit.MINUTES);
} catch (InterruptedException e) {
System.out.println(sqsMessage);
Thread.currentThread().interrupt();
}
try {
client.close().await(1, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
private void doSend(ApnsClient client, UserData data, CountDownLatch latchForClose) {
String pushToken = String.format("dummy_for_%s", data);
String payload = String.format("test for %s", data);
String collapseKey = String.format("collapse_key_for_%s", data);
// start sending a notification to APNs
Future<PushNotificationResponse<SimpleApnsPushNotification>> future = client.sendNotification(
new SimpleApnsPushNotification(
pushToken,
ApnsUtils.APNS_TOPIC,
payload,
null,
DeliveryPriority.IMMEDIATE,
collapseKey
)
);
// add listener to handle the result
future.addListener(completedFuture -> {
latchForClose.countDown();
Object response = completedFuture.getNow();
// do post process with response
});
}pushy の client は、利用後 close しないとメモリリークすることがわかっています。
doSend を block せずにこれを回避するため、別途 close 用の worker を用意して、担当の配信処理がすべて終了した後 close するようにしています。
実際に修正前後の擬似コードを用いて、一つ一つの通知配信処理の実行時間 (SQS から dequeue し APNs への配信が終了するまで) を計測してみると、以下のようになります。
擬似コード上ではありますが、この修正で 平均値に着目すると 50% 近く処理時間を削減できています。また、最大値も大きく改善しており、長く待たされるユーザへの影響が減りました。
| 実装 | 平均値 | 中央値 | 99 パーセンタイル値 | 最大値 | 最小値 |
|---|---|---|---|---|---|
| 問題のあったバージョン | 8,625 | 8,622 | 16,464 | 20,792 | 1,747 |
| 最初の修正後 | 4,622 | 4,720 | 7,017 | 12,987 | 1,936 |
- 試行回数
100 - SQS のメッセージ数
1,000 - SQS メッセージ内のユーザ数
10 - 単位
ミリ秒(小数点以下切り捨て) - 擬似コードでの再現値であり、実際の数値とはことなります
これにてまずは一件落着……と思いきや、次の問題が発生しました。
対応 2: 速くなったのもつかの間、また遅延
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!
残念ながら、平穏な日々は長くは続きませんでした。もう一度、遅延が発生したのです。
次の配信遅延は、高機能化したプッシュ通知をより多くのユーザに配信していく上で発生しました。
最初の対策のおかげで今回の遅延発生後の配信速度は以前の水準ではあったものの、早急に対策を行いました。
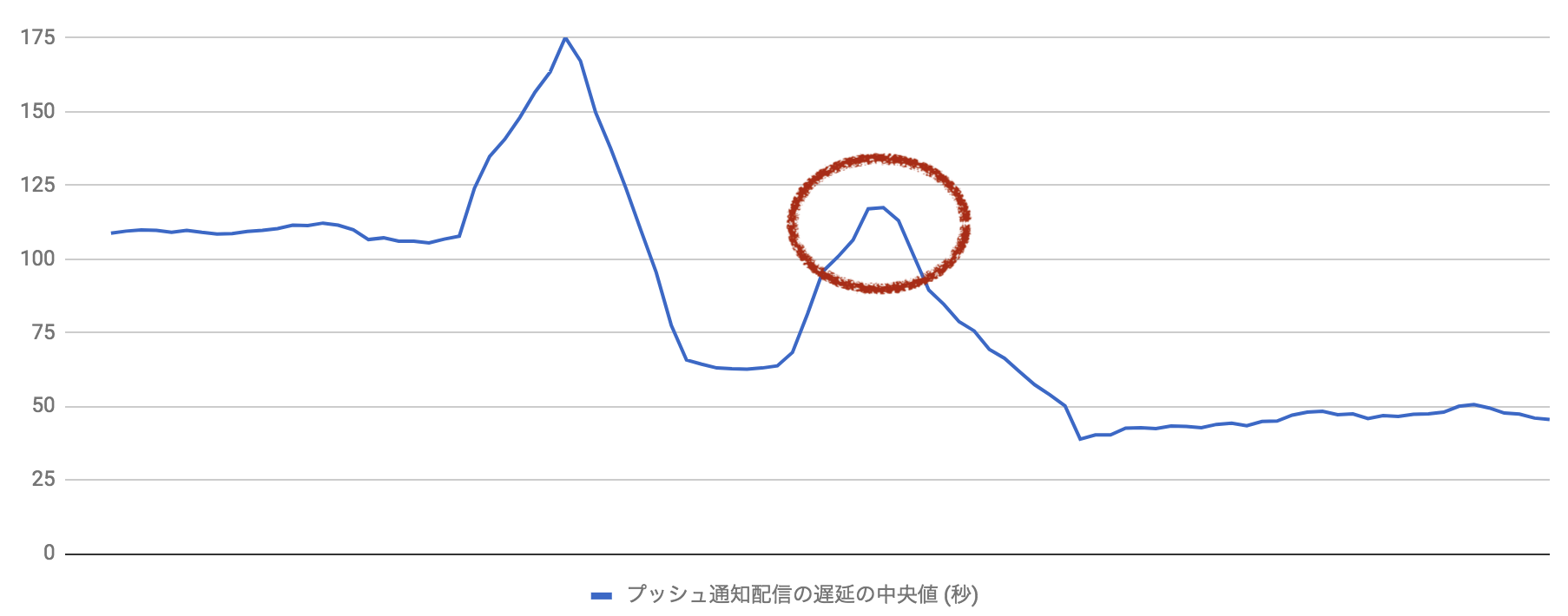
二つ目の遅延
これに対して、「最初の遅延が解消されたバージョンの副作用として、より多くの SQS メッセージがこれまでより高速に処理されるようになった。それが原因で引き起こされる問題があるのではないか」という仮説をたてて検証を開始しました。
検証
この仮説を検証するために、再度SQS のメッセージの量を変化させ、それに含まれるユーザごとの配信情報一つ一つの処理終了までの時間を計測しました。
以下は、擬似コードにより複数回検証を行った際の数値です。実際の数値とはことなりますが、おなじ傾向を持ちます。
| SQS のメッセージの量 | 平均値 | 中央値 | 99 パーセンタイル値 | 最大値 | 最小値 |
|---|---|---|---|---|---|
| 100 | 1,693 | 1,696 | 1,950 | 1,986 | 1,390 |
| 500 | 2,991 | 3,093 | 3,684 | 3,955 | 2,107 |
| 1,000 | 4,092 | 4,033 | 6,083 | 6,511 | 1,813 |
| 2,000 | 7,245 | 7,245 | 46,900 | 49,057 | 2,037 |
- 試行回数
100 - SQS メッセージ内のユーザ数
10 - 単位
ミリ秒(小数点以下切り捨て) - 擬似コードでの再現なので、実際の数値とはことなります
このように、SQS のメッセージの量が増えるに従って、各通知配信処理の遅延の最大値の悪化が目立つことがわかりました。
また、処理のログを確認すると、APNs との接続確立の失敗を示すログが多く出力されていました。
[nioEventLoopGroup-619-1] io.netty.handler.ssl.ApplicationProtocolNegotiationHandler [id: xxx, L:/xxx.xxx.xxx.xxx:xxxxx - R:xxxxx/xxx.xxx.xxx.xxx:443] Failed to select the application-level protocol:
java.io.IOException: Connection reset by peer
...
[nioEventLoopGroup-251-1] io.netty.handler.ssl.ApplicationProtocolNegotiationHandler [id: xxx, L:/xxx.xxx.xxx.xxx:xxxxx - R:xxxxx/xxx.xxx.xxx.xxx:443] TLS handshake failed:
javax.net.ssl.SSLException: handshake timed out
at io.netty.handler.ssl.SslHandler.handshake(...)(Unknown Source)
問題: APNs クライアントを不必要に多く生成していた
APNs との通信まわりの処理をみてみると、SQS からのメッセージを受け取るたびに APNs クライアントが生成されていることがわかりました。
以下が該当箇所のコードです。
public void sendAsync(SQSMessage sqsMessage) {
ApnsClient client = ApnsUtils.generateApnsClient();
if (client == null) {
return;
}
List<UserData> dataList = sqsMessage.getDataList();
CountDownLatch latchForClose = new CountDownLatch(dataList.size());
dataList.forEach(data -> sendWorker.submit(() -> doSend(client, data, latchForClose)));
// close client after all the messages are sent.
closeWorker.submit(() -> {
try {
latchForClose.await(3, TimeUnit.MINUTES);
} catch (InterruptedException e) {
System.out.println(sqsMessage);
Thread.currentThread().interrupt();
}
try {
client.close().await(1, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}APNs クライアントの大量生成がパフォーマンスに影響することを確認するために、実際に pushy の APNs クライアント生成のロジックを覗いてみました。
- pushy の APNs クライアントである
ApnsClientが生成される際、そのコンストラクタ内でNioEventLoopGroupが single thread で確保されます。また、ApnsChannelPoolという、APNs との接続を保持する Channel の pool が出来上がります。 - 実際の配信処理である
ApnsClient#sendNotificationでは、その pool から APNs との有効な接続をもつ Channel を取得(または作成)し、配信処理とその結果の待受を行っています。 - APNs との同時接続数が増えすぎてしまうと、Channel の取得に失敗する場合があります。Apple 側から DoS 攻撃だと認識され、その結果上記ログにある通り、接続を切断をされたり、接続確立に時間がかかったりするようになる場合があるためだと考えられます。Apple の開発者ガイドにも、Best Practices for Managing Connections としてその旨の記載があります。
このように、機能の展開につれて、SQS を流れるデータがより多くなったことと、前回の修正により sendWorker の詰まりが解消していることにより、大量の APNs への接続が一度に生成されることとなり、遅延の拡大に影響があったものと判断しました。
対応と結果
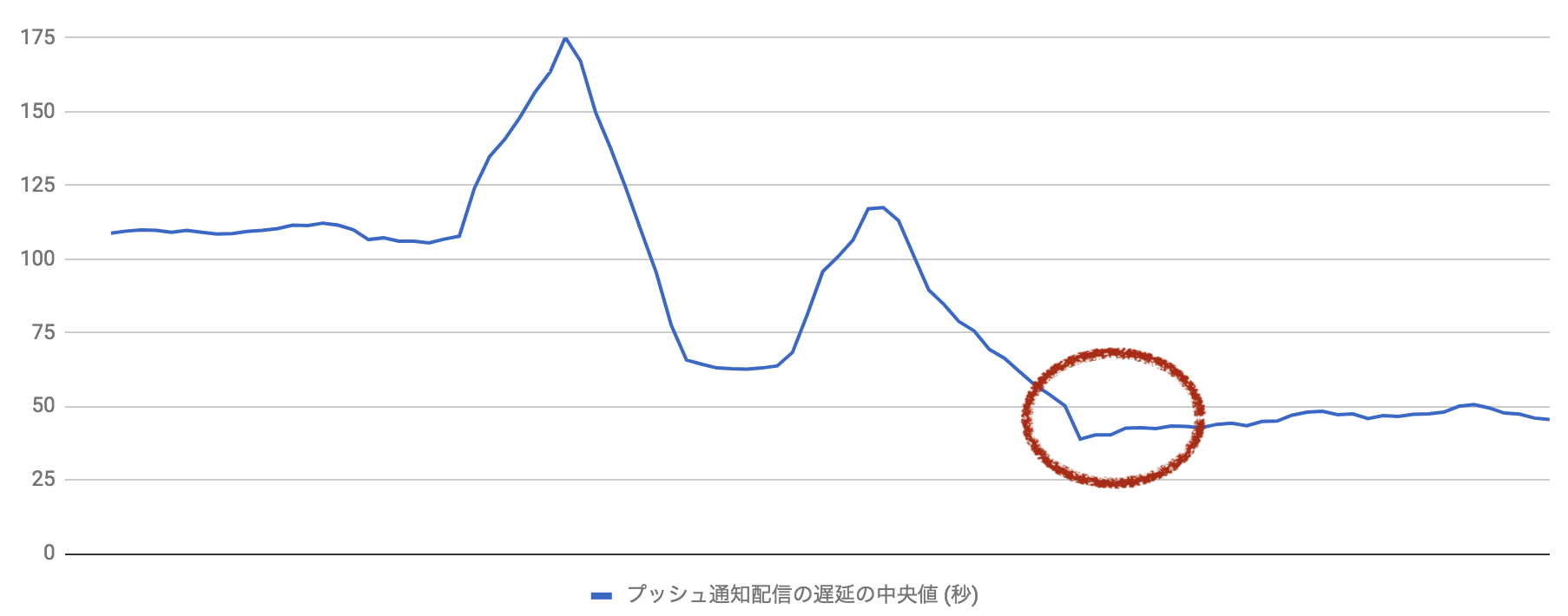
二つ目の遅延の解消
singleton の pushy の APNs クライアントを生成しすべての配信処理で使いまわすようにして、遅延を解消することができました。
- pushy の Wiki の Long-lived resources にも、 “We recommend creating a single client (per APNs certificate/key), then keeping that client around for the lifetime of your application.” と、singleton なクライアントの利用を勧める記載があります
- また、コントリビュータからのコメント にも
You don't need to—and shouldn't—open a new connection for each push notification.とあり、送信のたびに接続を開くのは推奨されていません。
この修正適用後の擬似コードは以下のようになります。
public class FixedSender2 {
private final ExecutorService sendWorker;
private final ApnsClient client;
public FixedSender2(int sendConcurrency, CountDownLatch countDownLatch) {
this.sendWorker = Executors.newFixedThreadPool(sendConcurrency, new ThreadFactoryBuilder()
.setNameFormat("fixed-sender-2-send-%d")
.build()
);
this.client = ApnsUtils.generateApnsClient();
}
public void sendAsync(SQSMessage sqsMessage) {
if (client == null) {
return;
}
List<UserData> dataList = sqsMessage.getDataList();
dataList.forEach(data -> sendWorker.submit(() -> doSend(data)));
}
private void doSend(UserData data) { /* Almost same as FixedSender1 */ }
public void destroy() {
if (this.sendWorker != null) {
this.sendWorker.shutdown();
try {
this.sendWorker.awaitTermination(1, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
this.sendWorker.shutdownNow();
}
}
if (this.client != null) {
try {
this.client.close().await(1, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}実際に修正前後の擬似コードを用いて、先ほどと同じように一つ一つの通知配信処理の実行時間を計測してみると、以下のようになります。
擬似コード上ではありますが、この修正で 40% 近く処理時間を削減できています。
| 実装 | 平均値 | 中央値 | 99 パーセンタイル値 | 最大値 | 最小値 |
|---|---|---|---|---|---|
| 問題のあったバージョン | 8,625 | 8,622 | 16,464 | 20,792 | 1,747 |
| 最初の修正後 | 4,622 | 4,720 | 7,017 | 12,987 | 1,936 |
| 二つ目の修正後 | 2,853 | 2,847 | 5,194 | 7,123 | 811 |
- 試行回数
100 - SQS のメッセージ数
1,000 - SQS メッセージ内のユーザ数
10 - 単位
ミリ秒(小数点以下切り捨て) - 擬似コードでの再現なので、実際の数値とはことなります
結果
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!
配信の速度が問題発生前の 2 倍以上にまでスピードアップ
各問題に対してそれぞれ対応を行い、遅延を解消することができました。
また、問題が発生する前と比べて配信の速度を 2 倍以上にまでスピードアップさせることができました。
本番環境においては、すべてのユーザのみなさまに対して、中央値で 1 分以内、99 パーセンタイル値でも 1 分半以内の配信性能を実現していることを計測から確認しています。
- 一つの処理性能の悪化が全体に影響することがあった問題に対しては、
parallelStreamではなく、ExecutorServiceを利用して並列処理を行うようにしました。 - 不必要なブロック処理は、通知配信処理の結果待ち合わせを Netty に任せるようにしました。
- pushy クライアントを不必要に多く生成していたため、singleton の pushy のクライアントを生成し、すべての配信処理で使いまわすようにしました。
まとめ
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!
こう書いてみると当たり前なのですが、OSS や JDK など、利用しているライブラリの内部のしくみについてしっかりと知る ことは、システムの性能にとってとても重要だということを改めて感じました。
そして、仮説 → 検証のサイクルを高速に回すことは、問題を発見・解決する上で無くてはならない動作でした。
また、これらに加えて以下の教訓を得ることが出来ました
- 計測できないものは改善できない
- (性能が良くなる場合も) ある変更がシステム全体に対する副作用をつねに考慮する必要がある
どれもシステム開発では当たり前の考えですが、これらを改めて徹底し、今後も良質な情報を届けるシステムを開発・運用し続けていきます。
We’re hiring!
- SmartNews のプッシュ通知配信とその遅延の影響
- 対応 1: iOS への配信が遅れている?
- 対応 2: 速くなったのもつかの間、また遅延
- 結果
- まとめ
- We’re hiring!

We're hiring!
スマートニュースでは、コンテンツ配信システムを支えるエンジニアを大募集しています。多くのチャレンジングな課題が待ち受けており、エンジニアとしてとてもエキサイティングな環境です。また、このプッシュ通知配信システムを始め、技術力が価値としてユーザのみなさまへダイレクトに届く機能がたくさんあります。
ぜひ、われわれと一緒により良いシステムをつくり、より良い価値を世の中に届けていきませんか?