こんにちは、スマートニュースの徳永です。深層学習業界はGANだとか深層強化学習だとかで盛り上がっていますが、今日は淡々と、ニューラルネットワークの量子化の話をします。
TL;DR
- パラメータだけを量子化するのであれば、ほぼ精度を落とさずに、パラメータのデータ容量は1/16程度にまで削減できる
- パラメータ、アクティベーション、勾配のすべてを量子化し、推論だけでなく学習までもビット演算だけで実現する研究が進んできている
- 現在は深層学習 = GPU必須というぐらいの勢いがあるけど、量子化の研究が進むと、今後はどうなるかわからないよ
はじめに
情報理論における量子化とは、アナログな量を離散的な値で近似的に表現することを指しますが、本稿における量子化は厳密に言うとちょっと意味が違い、十分な(=32bitもしくは16bit)精度で表現されていた量を、ずっと少ないビット数で表現することを言います。
ニューラルネットワークでは、入力値とパラメータから出力を計算するわけですが、それらは通常、32bitもしくは16bit精度の浮動小数点(の配列)で表現されます。この値を4bitや5bit、もっと極端な例では1bitで表現するのが量子化です。1bitで表現する場合は二値化(binarization)という表現がよく使われますが、これも一種の量子化です。
量子化には、計算の高速化や省メモリ化などのメリットがあります。なお、入力値と書きましたが、中間のレイヤーに対する入力値は入力値と書くよりはアクティベーションと書いたほうがよさそうなので、以下ではアクティベーションと表記することにします。
ニューラルネットにおいて、数値で表現されるのはパラメータ、アクティベーション、(パラメータ更新時の)勾配の3種類ですが、どこをどれぐらいの精度で量子化するのかは手法によって違ってきます。
推論時のパラメータを二値化する系
それでは、ニューラルネットワークの量子化に関する近年の研究を、特徴に基づいて分類していきましょう。
ニューラルネットの二値化と言った場合、どこを二値化するかで原理的には7つのパターンがあり、より厳密なことを言い出すと、学習の時に二値化するのか推論時だけ二値化するのかというバリエーションがあり、話がややこしいのですが、まずは推論時のパラメータのみを二値化する場合から紹介を始めます。
パラメータのみを二値化した場合、主なメリットはメモリ消費量の削減になります。速度面については、乗算を減らせるというメリットはありますが、既存のCPU、GPUのような演算回路でこのメリットを大幅に享受することは難しいでしょう。(FPGAやASICでは、面積が大きくなりがちな乗算回路を減らせることは大きなメリットになります。)
BinaryConnect: Training Deep Neural Networks with binary weights during propagations
Courbariauxらは、学習時にはパラメータの値を実数で保存しておき、forwardの計算の際に、実数のパラメータを二値化することで、MNISTやCIFAR-10, SVHNなどのデータセットにおいて、二値化したほうがむしろエラー率が低下する事を示しました。また、パラメータを二値化する際、確率的に二値化した方が良い結果が得られることを示しました。確率的な二値化はかなり重要で、単純にしきい値を設けて決定的に二値化すると、エラー率は上がってしまいます。
推論時のパラメータとアクティベーションの両方を二値化する系
より大胆に、パラメータとアクティベーションの両方を二値化した場合、メモリ消費量と速度の両方で大きなメリットが得られます。アクティベーションに使うメモリ消費量も減るので、すべてを32bit浮動小数点で表現していた場合と比較すると、メモリ消費量は単純に約1/32になります。速度面では、内積の計算がXNOR + popcountになるので、64個分の浮動小数点の積和演算を、数個のビット演算系の命令に置き換えることができます。ニューラルネットの計算はほとんどが内積の計算だと言っても過言ではないですから、圧倒的な高速化が実現できます。最近のCPUだとAVX命令を使えば8個分のFMA(Fused Multiply-Add)が一気に計算できるわけですが、それでもまだ埋められないぐらいの速度差があります。
BinaryNet
- Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
- Binarized Neural Networks
Courbariauxらは、BinaryConnectの工夫に加え、アクティベーションの値も二値化しても、ニューラルネットワークが動作することを示しました。単に二値化してしまうと勾配が0になってしまって学習ができないという問題がありますが、straight-through estimatorという近似的な手法を使って勾配を計算します。
Hubaraらもほぼ同時期(厳密には、arxivへのアップロードはHubaraの方が1日早かった)にほぼ同じ手法を提案していますが、Hubraらの手法は、以下のようなハードウェア実装を意識した工夫が施されています。
- shift-based batch normalization: batch normalizationを計算する際に、乗算をシフト命令で済ませられるよう、スケーリングを2のべき乗の値にのみ制限する
- shift-based adamax: 乗算をシフト命令で代替できるようにしたadamaxの変種アルゴリズム、最適化に使う
なお、先程論文をチェックしたら、Courbariauxらの論文のv3から、Hubaraらが著者陣に加えられており、内容にもHubaraらのshift-based batch normalizationなどが取り込まれていることに気づきました。なにが起こっているのかは外部からはよくわかりませんが、なにやら著者陣の間でやり取りがあったみたいです。
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
BinaryNetはMNISTやCIFAR-10, SVHNといった比較的小規模のデータセットではstate of the artに近い結果が得られましたが、ImageNetを使った実験では精度の大幅な低下が避けられませんでした。ネットワーク構造としてAlexNetを用いた場合、Full PrecisionではTop-5 accuracyが80.2%であるのに対し、BinaryNetでは50.42%と、大幅に精度が下がってしまいます。
Rastegariらは、行列を近似する際に、単に二値化するのではなく、出力がなるべく元の行列に近くなるよう、レイヤーごとにスケーリング係数を用意することで、精度が大幅に向上することを示しました。重みだけを二値化した場合、BinaryNetの61.0%に対し79.4%と大幅な精度向上を果たし、元のAlexNetの80.2%にかなり近い精度が出せる事を示しました。また、重みとアクティベーションの両方を二値化した場合も、Top-5 accuracyで69.2%と、これまでの50.42%よりも大幅に精度が向上することを示しました。
スケーリングで必要な計算量は行列積や畳み込みに比べるとかなり小さいので、速度面でのオーバーヘッドは小さいはずですが、乗算は乗算ですので、ハードウェア化を考えるとなくしたいよなぁ、という気持ちになります。乗算の代わりにshiftでなんとかならないかなぁ。
推論時のパラメータを三値化する系
三値化も、効率を考えると二値化と同じぐらい、非常に魅力的な選択肢です。二値化よりも精度が向上するのは当然ですが、値として0が使えるので、スパース化と組み合わせて、計算効率をさらに向上できる可能性があります。
Ternary Weight Networks
Liらは、パラメータを三値化しつつ、MNIST, CIFAR-10, ImageNetで32bit浮動小数点でパラメータを表現した場合に近い精度を達成しました。ResNet-18をベースのモデルとして、32bitのモデルでTop-5 accuracyが86.76%であるのに対し、3値のモデルでも84.2%の精度を達成できることを示しました。
この手法では、XNOR-Networkと同じくスケーリング係数を用いています。そのため、まずパラメータ$W$から三値化したパラメータ$W^t$を作り、それからスケーリング係数を決めます。しきい値$\Delta$よりも絶対値が小さいパラメータの値は0、それより絶対値が大きいパラメータは+1 or -1を割り当ててやることにします。
1/3の要素を0にすることを考えると、パラメータは一様分布であると仮定するとしきい値$\Delta$は$\frac{2}{3}\mathbf{E}(\left|\mathbf{W}\right|)$に、正規分布に従うと仮定すると$0.7\mathbf{E}(\left|\mathbf{W}\right|)$となります。ただし、$\mathbf{E}(\left|\mathbf{W}\right|)$は行列$W$の各要素の絶対値の平均です。
$W^t$が決まってしまえば、スケーリング係数は閉じた形で求めることができます。
Trained Ternary Quantization
Zhuらは、LiらのTernary Weight Networkを改良し、より高精度化できる事を示しました。具体的には、スケーリング係数をレイヤーごとに2つ用意し、+側と-側でスケーリング係数を変えられるようにしました。スケーリング係数自体はバックプロパゲーションで学習します。また、しきい値を適用して三値化する前にレイヤーごとにパラメータの取りうる値の範囲を$[-1, +1]$に正規化してから量子化を行うなど、他にも細かい工夫が入っています。ResNet-18をベースにした実験では、元の32bit浮動小数点でのネットワークがエラー率10.8%、LiらのTernary Weight Networkが13.8%、提案手法では12.8%のエラー率となっています。
また、CIFAR-10での実験では、場合によっては三値化した方が精度が上がる場合がある事も示しました。
Training Ternary Neural Networks with Exact Proximal Operator
Liら, Zhuらは、三値化の際にヒューリスティックにしきい値を設定していました。
Yinらは、パラメータ行列の近似精度という意味で、三値化におけるしきい値の決定方法には閉じた解法があることを示しました。行列$W$の三値化を制約付き最適化問題だとみなすと、最適な1の数、0の数、-1の数を閉じた形で求めることができます。最適な数が求まれば、後は値が大きいものから順に1、0、-1を割り当てていけば三値化ができます。
MNISTとCIFAR-10で実験を行い、提案手法はLiらTWNよりも精度が高いことを示しました。Zhuらの手法については、閉じた形で解が求まるとしていますが、実験はしていないようです。LiらのTWNと、TWNをベースに三値化部分だけ改良した提案手法での比較となっていました。
実験がMNISTとCIFAR-10だけで少しさみしい感じですが、パラメータだけを三値化する場合、ImageNetでもかなり良い結果が出せることはLiら、Zhuらが既に示しているので、この手法もImageNetにも応用できるでしょう。
二値化、三値化以外の量子化
ここからは、二値化、三値化以外の一般的な量子化についての研究を紹介しましょう。値としてとり得る自由度が上がる分だけ精度も上げやすいこともあり、パラメータとアクティベーションの両方を量子化する研究が多いようです。
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
Zhouらは、パラメータ、アクティベーションに加え、勾配を量子化しても学習ができることを示しました。かなり多くのパターンで実験をしており、例えば、ベースとしてAlexNetを用いたImageNetに対する実験では、元のネットワーク(32bit精度)ではTop-1 accuracyが0.559であり、パラメータ、アクティベーション、勾配の全部を8bitに量子化した場合にはTop-1 accuracyが0.530に下がること、パラメータ1bit、アクティベーション4bitに量子化(勾配は32bit精度)した場合、Top-1 accuracyが0.503 or 0.530 (後者はAlexNetをパラメータの初期化に利用)であったことなどを報告しています。
また、勾配を量子化する場合、勾配に一様分布から生成したノイズを加えてから量子化する事が重要であったと報告しています。ノイズを加えてからの量子化は、一種の確率的な量子化であるとみなせるので、なんとなく納得はいきます。
Convolutional Neural Networks using Logarithmic Data Representation
Miyashitaらは、ニューラルネットワークの量子化について、いくつかの条件で実験をしています。アクティベーションのみを量子化した場合、アクティベーションとパラメータの両方を量子化した場合、アクティベーション、パラメータ、勾配を量子化した場合について実験を行いました。
- 低ビット表現方式として、ログ量子化表現を使うこと、ログ量子化されたベクトルの内積をシンプルなビット演算で近似することを提案しました。
- ImageNetを用いた実験で、アクティベーションとパラメータの両方を量子化した場合、アクティベーションに4bit、パラメータに4bitを割り当てれば、AlexNetやVGG16をほぼ精度低下なしに量子化できることを示しました。(当然、アクティベーションのみを量子化した場合、精度低下はより少なくなります。)
- CIFAR-10を用いた実験で、アクティベーションとパラメータに加えて勾配も5bitに量子化しても学習ができることを示しました。この条件では、線形の量子化では学習がうまく進められず、ログ表現が必要でした。これは、DoReFa-NetでのZhouらの報告と一致します。(DoReFa-Netは線形の量子化を使っている)
ログ表現は直感的にはとてもよさそうに思えるのですが、実は線形の量子化の方が概ね精度面では上回ったそうです。ログ表現の基数を2から$\sqrt{2}$に変える改良を施すことで、多くの場合で線形量子化よりも良い結果が得られました。
FPGAやASICなどでのハードウェア化を強く意識した研究ですが、CPUでもビット演算を使ってこの低精度表現のメリットを享受できるのではないかと、頭をひねりたくなる魅力があります。(今のところ、アクティベーション4bit+パラメータ4bitで、8bit単位でlook up tableを引く、というぐらいしか、自分の中ではアイデアが出てきていません。)
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
Hubraらは、Miyashitaのログ表現を用いたニューラルネットの量子化がかなり汎用的に使えることを実験で示しました。Miyashiraらは畳み込みニューラルネットのみを対象として実験していましたが、HubraらはLSTMのように、自然言語処理で使われるモデルを対象とした実験も行っています。
Soft Weight-Sharing for Neural Network Compression
Ullrichらは、パラメータの取りうる値の事前分布として混合ガウス分布を設定することで、値の取りうる範囲をふんわりと制限しました。混合ガウス分布のパラメータ自体も学習時に最適化の対象となるので、結局、線形量子化やログ量子化のように人間が頑張って量子化をするのではなく、データにいい感じの量子化のしきい値を決めさせていると捉えられます。
また、この解き方により、値が0になるパラメータがたくさん出てくるので、量子化と同時にスパース化も行えます。
Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights
Zhouらは、いきなりパラメータを全部量子化するのではなく、パラメータの半分だけ量子化してから再学習を行い、残ったパラメータの半分をまた量子化、といった感じでインクリメンタルに量子化の手順を進めることで、AlexNetやGoogleNet、ResNetなど、多くのネットワークにおいて、量子化後の方がむしろ精度が向上することを示しました。32bit浮動小数点でのResNet-50は、ImageNetでのTop-5 error rateが8.76%ですが、これを5bitに量子化すると、Top-5 error rateが7.55%にまで下がります。省メモリ化と同時に高精度化を実現しており、非常に興味深い研究です。
アクティベーションの二値化における重要なテクニック
アクティベーションを二値化するのは、アクティベーションにステップ関数を適用してから次のレイヤーに入力することほぼ(=小さい側の値が0ではなく-1なのがステップ関数と少し違う)と同じですから、そういう非線形な関数を適用している、と数式上で真面目に考えてバックプロパゲーションの計算を行うと、ほとんどいたるところで勾配が0になってしまいます。そこで、forward時はステップ関数(しつこいけどちょっと違う)なんだけど、backward時には$(-1, -1)$から$(1, 1)$の間を直線でつないだ関数を考えます。これをStraight Through Estimator (STE)と言います。STEの形を次の図に示します。
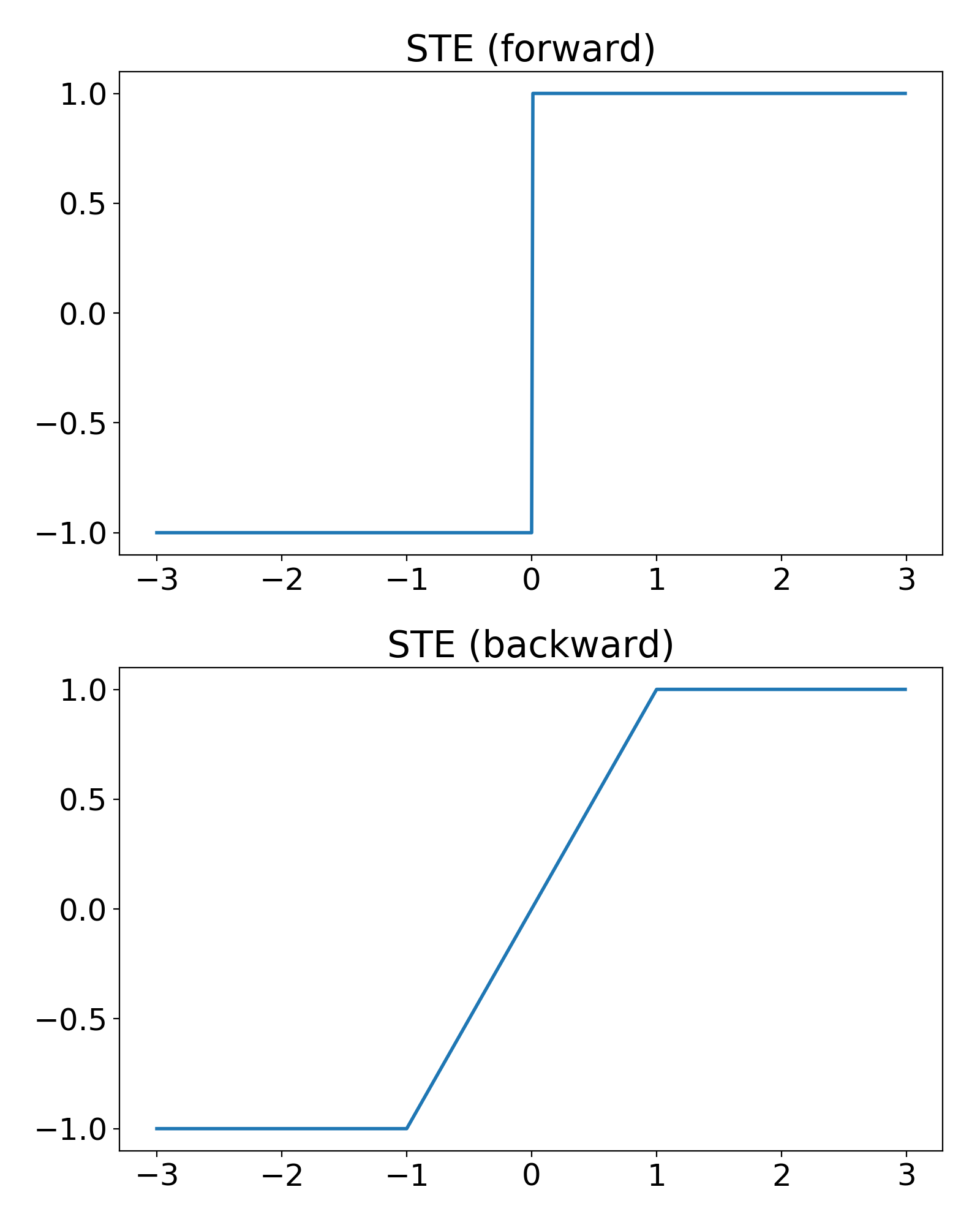
こういう関数を適用しているんだと思って計算することで、いい感じの勾配が計算できて、バックプロパゲーションで学習をすすめることができます。
おそらく、これが二値化におけるいちばん重要な技術です。
まとめ
近年の量子化の研究はおそろしいほどのスピードで進展しています。パラメータだけを量子化するのであれば、三値化+スケーリング係数で、ほぼ精度を落とさずに、パラメータのデータ容量は1/16程度にまで削減できることがわかってきました。モバイルアプリにResNet-50の約100MBのモデルを組み込むのは非現実的ですが、100/16 = 6.25MB程度であれば、もうちょっと圧縮すれば、十分に組み込めるサイズです。モバイルデバイスで深層学習を使ったアプリを実現する上での困難はなくなってきました。
その他、勾配も量子化しつつ学習する方法や、量子化しつつむしろ精度を上げる方法など、いろいろな方面へと研究が進んでいます。
今後の研究の方向性はいくつか考えられます。個人的には、最も有力なのは、FPGAもしくはASICのみで学習する(GPUは使わない)、という方向性かなと予想しています。今回紹介したいくつかの論文は明らかにハードウェア化を意識していますし、紹介しなかった論文にも、FPGAで二値化を実装、みたいなものは数多く見受けられます。そうすると、パラメータ、アクティベーション、勾配、すべてを量子化しつつ、どれだけ精度を落とさずに学習できるのかというところが今後の研究の焦点となっていくでしょう。
一方、個人的には、CPUでの推論の高速化に興味があります。パラメータとアクティベーションを二値化した場合にはXNOR+popcountで高速化できることがXNOR-Netでも示されていますし、パラメータ側を三値化するぐらいまでは自明な拡張として考えられますが、パラメータもアクティベーションも3bitぐらい使うような設定でビット演算で高速化できるのか。興味を持つ人は少なそうな雰囲気を感じますが、実用上は割と重要なのではないかなと考えています。
ニューラルネットの学習に使われるハードウェアの勢力図は今後どう変化していくか
現在の深層学習では、NVIDIAのGPUがもてはやされていますが、シンプルなビット演算だけでニューラルネットの学習が実現できるのであれば、世界が変わってきます。これまでは、推論がCPUでできるなら負荷が低い場合はCPUで安く上げられるね、ぐらいの話だったのが、シンプルな専用チップで、GPUより高速に、GPUより効率よく学習できる可能性が見えてきたわけです。大量の浮動小数点演算が必要であればGPUが最適解になるという事実はそうそう動きませんが、浮動小数点演算が不要になった時点で、回路規模が大幅に小さくできるようになるので、戦いの前提条件が大きく変化することになります。
チップの製造には年単位の時間がかかりますし、学習がここまでシンプルなビット演算でできるというのは2016年の研究でわかってきたことですから、量子化しつつ学習する専用チップがでてくるのは速くても2018年ごろになるでしょう。とはいえ、FPGAであればもっと早く物事を進められますから、FPGAで学習する事例は今年の後半ぐらいから徐々に出てきてもおかしくありません。(動きが速い会社はもう既に導入しているかもしれませんね。例えば、Microsoftは以前からBingでFPGAを使っていますし、既にいろんな取り組みをやっていると予測します。)
もちろん、NVIDIAもこの状況を手をこまねいてみているわけではありません。今回紹介した論文は、著者にNVIDIA所属のメンバーが入っているものが何本もありますし、ニューラルネットのスパース化についての論文もありました。製品を出すかはともかくとして、NVIDIAがGPU以外でのニューラルネットの学習について色々検討している可能性は高いでしょう。
NVIDIAのつらいところは、社内で深層学習専用チップを研究していたとしても、既存のGPUと市場がバッティングするため、製品化するタイミングが難しい点です。なんか、昔どっかの本で読んだような話題だな、と思ったら、 イノベーションのジレンマ でした。専用チップが市場をDisruptできるかどうかはニューラルネットという市場の大きさ次第で、確実に専用チップが勝つと決まっているわけではありません。GPUを持ってないベンダーであれば話はある意味簡単で、全力で専用チップを作って市場に投入するだけですが、GPUを持っているベンダー(NVIDIA、AMDの2社ぐらい?)は、専用チップを投入するべきか見送るべきか、製品化するとしたらタイミングはいつ頃なのか、色々悩まなければいけません。そう考えると、持てるものには、持てるものなりの辛さがありますね。
ITproの日の丸AIの挑戦 - 加熱するAIチップ開発、王者エヌビディアに日本勢が挑むという記事によると、日本でも何社か専用チップの開発に乗り出しています。USにあるNervanaというベンチャー企業は製品を出す前にIntelに買収されてしまいましたが、これはつまり、将来的にはIntelから製品が出てくるという意味でしょう。
大きな枠組みでは、CPUが勝つのか、GPUが勝つのか、FPGAが勝つのか、専用チップが勝つのかの4択が待ち受けています。それぞれの選択肢は背反ではなく、例えばCPUが深層学習用命令を実装することで実質的に専用チップの機能を取り込む、みたいな未来もあり得るでしょう。また、学習と推論で、勝者が違う可能性もあります。学習はFPGA、推論はCPU、みたいな未来もあるかもしれません。
そういうわけで、現状のNVIDIA一強状態が今後も続くという保証は特にありません。推論はローエンドではIntelやQualcommがCPUに実装した(ほぼ)専用命令と比較される状況になり、学習に関しても他のライバルと比較される状況になっていきます。今後どうなるかわからない、(野次馬の立場からすると)非常に面白い局面に入ってきました。
という訳で、量子化は単にちょっと効率が上がるよという話ではなく、深層学習ハードウェア業界の勢力図を塗り替えてしまう可能性を持った、重要な技術なのです。これからしばらく、注目すべき分野であることは間違いありません。
量子化に関係する論文リスト
力尽きてちゃんと読めず、紹介できなかった論文を最後に上げておきます。他にも、FPGA化したらこれぐらい電力効率が上がった、みたいな論文は何本もあるようです。
- Ternary Weight Decomposition and Binary Activation Encoding for Fast and Compact Neural Network
- Ternary Neural Networks for Resource-Efficient AI Applications
- Loss-aware Binarization of Deep Networks
- Improving the speed of neural networks on CPUs
- 量子化と直接的な関わりはありませんが、CPUでSSE命令を使って効率化するためにはどういうコードを書けばよいか、参考になります