スマートニュース、データサイエンス・マシンラーニングチームの高橋力矢と申します。記事選定や広告ターゲティングといった、高度な機械学習アルゴリズムを必要とする仕事全般に携わっています。 記事や広告を選択する際には、 人の好みをアルゴリズムで予測する必要があります。本エントリーでは、機械学習と近年流行った行動経済学とをつなげる試みを通じて、人の好みや選択規範がどれだけ機械的に予測できるものかについて、ご紹介したいと思います。
San Diegoの風にふれて

Mission Bay
San Diegoは米国カリフォルニア州南部の、メキシコとの国境付近にあるリゾート地です。米国海軍の基地があることで有名ですが、La Jolla ShoreやMission Bayに代表される、マリンリゾート・マリンスポーツのメッカでもあります。加えて、University of California, San Diego (UCSD) という、認知科学と生物学では全米トップクラスの研究機関を擁しています。

UCSD Library nearby Cognitive Science labs
行動経済学や、その密接な関連分野である計算神経科学・認知科学の研究に関わるものにとって、San Diegoは憧れの地です。そのSan Diegoにて、機械学習研究の国際会議 ICLR および AISTATS が5月中旬に開催されました。筆者はこのICLR & AISTATSに参加して一流の研究者と交流する機会に恵まれた上に、自著論文を発表・紹介する貴重な場を頂きました。そして最終日にはUCSDを訪問し、機械学習と人間心理の双方に通じた心理学者たちと深いディスカッションも行ってきました。
- International Conference on Learning Representations (ICLR) http://www.iclr.cc/doku.php?id=iclr2015:main 最近何かと話題の多いDeep Learning技術に特化した国際会議です。
- AI & Statistics (AISTATS) http://www.aistats.org Deep Learningに限らず、統計的機械学習アプローチ全般を扱った国際会議です。
筆者は、人間が意思決定する際に伴う「非合理性の度合い」を定量予測する機械学習モデルを提案しました。前職であるIBM東京基礎研究所勤務時代に執筆した論文本文が以下でご覧いただけます。 http://jmlr.org/proceedings/papers/v38/takahashi15.html
また、発表スライドが以下でご覧になれます。
合理性 = 一貫した目的関数 = 数理的利便性
そもそも合理性/非合理性とは何でしょうか。そしてなぜ非合理性に着目するのでしょうか。その答えは、スマートニュースがB2C (Business to Consumer) のサービスを提供しているから、です。B2Cのサービスにおいては、機械について考える前に、ヒト(human)について深く考える必要があります。一流のエンジニアは、実在の人間を理解するスペシャリストなのです。合理的(rational)という言葉は、巷では「賢い」と似た意味で扱われます。経済学だともう少しカッチリした意味で使われており、「その人の価値観においては一貫した目的関数に沿って行動している」くらいの意味を持ちます。たとえば炭水化物を延々と食べ続けて肥満に向かう人は、健康を大事にする人からは非合理的に見えるかもしれません。しかし、もしその人の目的関数が合計カロリーの最大化であれば、その人の中では合理的と言えるわけです。
SmartNewsでは、たくさんのニュース記事を機械的にスコアリングして、ユーザーの皆様が興味を持ちそうな記事をセレクトしています。記事Aと記事Bがあって、AよりBを読みたいと誰かが思ったら、その人にとっては(記事Bのスコア)>(記事Aのスコア)となるようなスコアリング関数が背後にあるだろう、と考えるのです。
このスコアリング関数を、多くの経済学者は効用関数(utility function)と呼んできました。その背後には、人により効用関数は違うけれども、同じ人の中ではこの関数は一貫している、という前提があります。B2Cのサービスで使われる行列分解(matrix factorization)、ランク学習(learning to rank)といったビッグデータによる推薦技術の本質は、個人の中では一貫した効用関数の推定なのです。「人の気持ちなんか少しもわからないけど数学にはめっぽう強い」エンジニアがいたとすれば、その人が使うツールは合理的個人の仮定+ビッグデータということになります。
効用関数が一貫した個人は、確かに「賢い」と言えます。誰かが悪意をもって撹乱しようとしても、ちぐはぐの行動が起きないので、騙されることがありません。しかしながらSmartNewsは、合理的個人モデルに頼り過ぎない記事推薦をするように設計されています。私たちには、ユーザーの皆様の判断を誤らせないよう、適切な推薦を行う責務があるのです。過去の研究が示すように、ヒトの判断や選好はコンテクストの与えられ方によって操作されやすいからです。
非合理性と定量予測の難しさ
合理的個人モデルは、我々が一貫しているかどうか真実を精査せずに使われます。しかし、その数学的な取り扱いの良さは世の中で役に立ってもいます。事実、主流となっている経済学は合理的個人同士が交渉するときの帰結を予測できるようにしてきましたし、いわば機械学習の親戚である計量経済学は、統計的に推定された効用関数の合計を通じて、需要予測に広く使われています。一方で、実験心理学者や認知科学者、行動経済学者たちは、そのような合理的個人モデル+ビッグデータ・アプローチが無効になる面白い例を考え出しました。データ・サイエンティストたちがビッグデータを使って複雑なことをやり始める遥か前に、彼らはもっと面白い実験を行っていたのです。
下図を見てください。ここでは、消費者のグループに、A・B・C・D・Eのどの商品が欲しいかを質問します。結果を劇的に浮かび上がらせるため、商品の属性は(価格, 品質)の二次元しかありません。そして、価格と品質とがトレードオフの関係にあります。
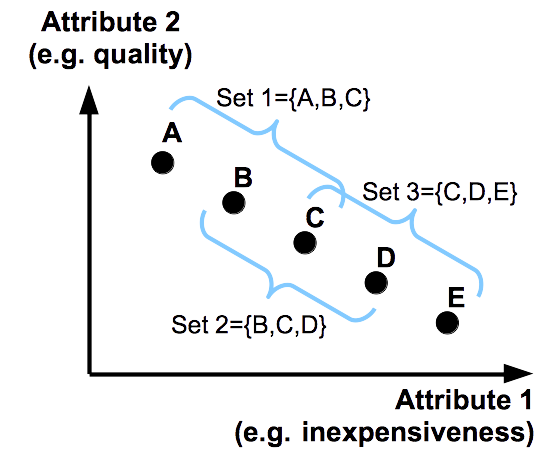
Simonson (1989)は、被験者をランダムに分けて、選択肢集合{A,B,C}を見せたグループ1、{B,C,D}を見せたグループ2、{C,D,E}を見せたグループ3で、それぞれ商品の選ばれ方がどうなるかを調べました。その結果、グループ1ではB、グループ2ではC、グループ3ではDが最も人気になりました。 この観測結果は、妥協効果(compromise effect)と呼ばれています。限られた選択肢集合の中で判断させると、見かけ上真ん中になっている商品が選ばれるということです。マージンが高く「売りつけたい」商品が真ん中にすえられ、操作された選択肢集合を呈示された場合、消費者は知らず知らずのうちに高値でものを買わされる可能性があります。このような操作にひっかかるヒトは、合理的とは言えないわけですね。
妥協効果は、効用関数アプローチも無効化してしまいます。効用関数を使う場合、商品の属性を多次元入力ベクトル、その商品の価値を一次元出力スカラーとして、出力スカラーが最大の商品が選ばれたと考えます。グループ1・2・3はランダムに分けられたので、平均的な効用関数はグループ間であまり変わらないことを思い出してください。この効用関数を商品の属性ベクトル(価格,品質)に適用することで、商品Aの効用、商品Bの効用、…、商品Eの効用が一意にあるはずで、(商品Bのスコア)>(商品Cのスコア) と (商品Bのスコア)<(商品Cのスコア) が両立することはありません。妥協効果が発生する状況においては、効用関数の形を線形にしようが、各次元に関して逓減的(品質が2倍になっても嬉しさは2倍より少ない)にしようが、もっと複雑な非線形関数にしようが、定量予測はできないことになります。機械学習エンジニアやデータ・サイエンティストにとっては面目丸つぶれです。
追い討ちをかけるようなさらに複雑なケースとしては、(出力[W],価格)の二属性で記述されたスピーカーを選ぶ (Kivetz et al., 2004) のような実験結果もあります。一番出力が低く価格も安いAから、出力最大で最高値のEまでの商品に対して、 {A,B,C} を見せたグループからはCが最も人気だったが {B,C,D} からはC、{C,D,E} からはDが選ばれるという結果でした。ここでの選択規範は、価格よりは出力を優先するという絶対的な効用と、真ん中を選ぶという妥協効果のミックスになっています。どういう場合にどちらの効果が勝るか定量予測するのは極めて困難です。ある種のad-hocな方法では、与えられた選択肢の中だけで、異なる商品間の価格の差額を説明変数とみなす、といったアイデアがありますが、この方法はどの商品とどの商品の差を入力すべきか定かではありません。特に、将来、商品AとCとZを見せたらどれが選ばれるだろう? というテストデータへの予測が、このad-hocなアプローチではできません。
一択の状況では、商品Bを買ったとしたら、商品Aは手にはいらないわけですから、商品Aの属性が商品Bの効用に影響しているのは不可解です。計量経済学や機械学習では、予測不能な部分はランダムノイズとして取り扱いますが、この非合理性はたくさんの人間を集めて平均しても残っているため、ランダムノイズとは違います。本当に人間の振る舞いを理解したければ、合理性で割り切った綺麗な数理モデルの安定した世界から飛び出さなければいけないわけです。ただし飛び出すといっても、きちんと定量予測ができること、という条件つきで…。はてどうやって?
個人を統計学者だと考える
著者は数理的に厄介なこの課題を解決するために、「ヒトは多重人格者であり、自分でも完全にはわかっていない効用関数を推定している存在」と仮定しました。「私」という単一主体が意思決定している、というのはフィクションであって、実際には脳の中の様々な組織の間の交渉(相互作用)によって出てきたものが人間の判断だ、と考えたわけです。 実際にはパラメータ推定をシンプルにするために二重人格モデルとし、一つ目の人格は通常の経済学のように効用を計算する存在とし、Utility Calculator (UC)と命名しました。UCは、効用を計算することだけができて、最終的な意思決定の権限がありません。彼は代わりに、商品の属性ベクトルと効用関数値のサンプルを、もう一人の人格: Decision Making System (DMS)に送ります。そしてDMSが最終的な意思決定の権限を持ちます。非合理性が生まれる源泉は、DMSのメカニズムにあります。彼はUCが使った効用関数を、完全には理解できません。加えて、UCが送ってきたすでに計算ずみのブラックボックスな効用値も、完全には信用しません。そこで、UCが使ったと思われる効用関数を再度自分で推定しにかかります。そのようにして得られた推定効用関数に基づいて最終判断を行います。つまりDMSは「統計学者」としてはたらいており、コンセプトとしては下図のように表現できます。UCが持っている本来の効用関数と、DMSが推定した近似された効用関数とが一致しないことに着目してください。
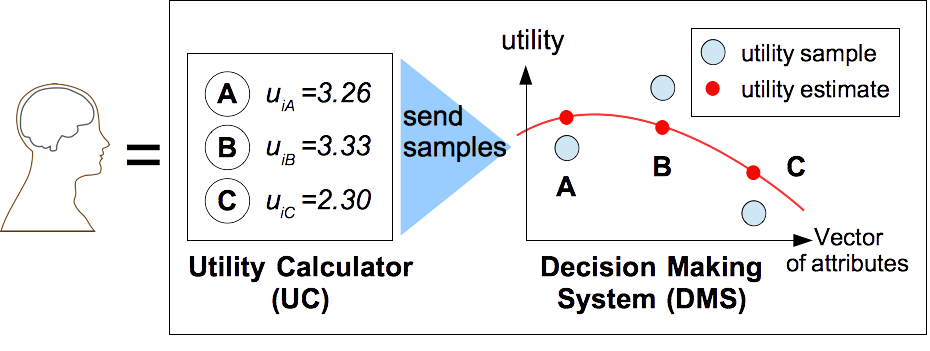
実装における詳細は次のようにまとめられます。ここから先を知りたい方はぜひスライドと論文を読んでみてください。DMSは過学習を避けるために事前分布を使ってベイズ縮小推定を行う、と前提しました。この事前分布が選択肢集合によって決まると仮定することで、著者のモデルは妥協効果を再現できます。このベイズ縮小推定はガウス過程回帰 (Gaussian Process Regression)としてモデル化されており、パラメータ推定値の大域最適解が計算可能になっています。大域最適性は、(商品集合, 選択された商品) の組み合わせに関するビッグデータがあった場合に、ある個人の中のUCとDMSの影響それぞれを正確に切り分けて推定できるようにしてくれます。
見かけの不合理性を超えて: 本能としてベイジアンな人々
提案された二重人格機械学習モデルを俯瞰すると、一見非合理な人間の選択規範も、制約されたリソースのもとではある種の合理的理由を持っているという発想が出てきます。狭い意味では非合理だが「深い合理性」を持っているという見方ができるのです。今回の論文は一つだけ商品を選ぶケースにおける予測モデルであり、複数の記事を読むことができるSmartNewsとは適用先が違います。しかし、ヒトを深い合理性を持ったベイズ統計学者とみなす基本思想は、ニュース記事の推薦にも多いに役立つであろうと考えています。深い合理性の源泉は、ベイズ縮小推定と事前分布にあります。通常の機械学習タスクでは、事前分布は既存データを過信する過学習を防止するために使われます。一方、人間は事前分布を「環境の不確実性を見込む」ために用いているのではないかと考えられます。著者のモデルを例にとれば、事前分布は目の前のコンテクストに対して決まるため、購入可能な商品の集合の変化に対して適応的です。
合理的個人と、ベイズ統計学者としてふるまう個人とを比較してみましょう。合理的個人は効用関数が固定しており、一貫してはいますが、その効用関数に固執し続けるため環境変化に対して脆弱です。仕事を例にとれば、安定した雇用のもとで着実で高精度なアウトプットが良しとされる世界が全てだと思って目的関数を設計すると、不安定でスピードが優先される社会にシフトしたときに不適応が顕著になります。一貫した効用関数という行動規範は、社会環境が変わった途端に使い物にならなくなるわけです。一方で、ベイズ統計学者な個人は、妥協効果という小さな代償の代わりに環境変化に対する深い適応性を備えており、広い視野のもとでは合理的とみなせるわけです。深い合理性を考えるアプローチは、少し離れた分野では進化心理学で盛んですが、この領域の学者は経済学的には非合理に見える行動も子孫を残すための行動としては合理的であることを見つけています。
人間をベイズ推定機械だとみなしてその行動を予測するアルゴリズムには将来性がありそうです。UCSDで議論をした研究者たちは、スロットマシンのように報酬がランダムに手に入るゲームを被験者たちにプレイしてもらうことで、人間が本能として不確実性を常に見込んでいることを発見しました (Zhang and Yu, 2013)。彼女らは高い予測精度を誇る機械学習モデルを設計していましたが、そのモデルでは、ゲームのパラメータが不変の場合でも、被験者たちはパラメータ変化(環境変化)を予見したベイズ統計学者のように振る舞うことになります。被験者の振る舞いは統制されたゲームの中だけでは最適ではなく非合理に見えますが、不確実性に常に備えているという点で本当の意味で「賢い」ように思えます。
機械学習には周辺分野が数多くあります。Deep Learningのブレイクによりコネクショニストと呼ばれるニューロンの発火を模倣するアプローチが再度脚光を浴びていますが、その陰で違ったタイプの生物模倣機械が勃興しつつあることを実感したSan Diego滞在でした。

References
- Simonson. Choice based on reasons: The case of attraction and compromise effects. Journal of Consumer Research, 16:158–174, 1989.
- Kivetz, O. Netzer, and V. S. Srinivasan. Alternative models for capturing the compromise effect.Journal of Marketing Research, 41(3):237–257, 2004.
- S. Zhang and A. J. Yu. Forgetful Bayes and myopic planning: Human learning and decision-making in a bandit setting. Advances in Neural Information Processing Systems, 26:2607-2615, 2013.