ゴクロ改め、スマートニュース株式会社の大平です。
巷間では「bigdata」の活用が叫ばれて久しいですが、弊社はまだまだ小さい規模のスタートアップのため少なくともデータサイズとしてhugeなdataの活用が行える環境ではありません。 であればデータの活用に対する要求が低いか、というとそうでも無く、サービスサイドでも自然言語処理や機械学習を中心としたデータ解析処理がサービスの生命線となっていますし、サービスの裏側でも戦略を立てる上で効果測定や諸々のデータの分析は非常に重要な位置を占めています。
本記事では主にサービスの裏側で求められるデータ解析において、いかにカジュアルにデータを解析するか、の一例として、掲題のような組み合わせによるデータ可視化の事例を簡単にですがご紹介したいと思います。
データ解析基盤を作る側の視点からすると、システムとして求められる要件は以下のようなものだと理解しています。
- データサイズに対するスケーラビリティ
- どんなにデータが増えてもシステムが破綻しない。
- 解析処理のリアルタイム性
- 発生したデータをリアルタイムに近い形でデータストアに保存できる
- データストアに蓄えられたデータを必要な時に必要な形で迅速に取得できる
- 結果の可視化の容易さ
- グラフや表を用いて、適切な形で可視化が行える
- 多面的なデータの取得や表示が行える。たとえばドリルダウン分析のような事が行える。
また、アドホックにデータ分析を行いたい場合、集計済みの数値データだけでなく生データに近いデータからの集計処理が必要になることが多いですが、そういった本来ヘビーな解析処理をできるだけ迅速に複数回実行できるようにするか、そういう環境も必要になってきます。
そして、個人的に一番難易度が高いと思うのが、データの適切な可視化をいかに手軽に行うか、です。
こういった要件を満たすシステムの構築を1から10まで自作するのは我々のようなスタートアップでは厳しいため、OSSや商用ソフトを組み合わせての実現を試みました。
Amazon Redshift

まずはデータを保存するデータベースですが、今回はAmazon Redshiftを採用しました。 http://aws.amazon.com/jp/redshift/
Redshiftは2013年2月に公開され、日本でも6月より使用が可能になった、一言で言うと従量課金で使用できるデータウェアハウス製品です。Netezzaなどと同様に列指向のアーキテクトとなっており、インターフェースとしてSQL(PostgreSQLのサブセット的扱い)が使用できる事から多くの既存のBIツールとの連携が行える事が特徴と言えると思います。 技術的にはBig Data関連のベンチャー企業Par Accelの技術が使われていると言われています。
Redshiftの技術面や使い方についての解説としては、ビッグデータ解析関連のサービスを提供されているハピルス社の藤川さん、宮崎さんが書かれている以下の連載記事が非常に分かりやすいので、本記事では詳細は割愛します。 [参考] Amazon Redshiftではじめるビッグデータ処理入門
使い手の視点から言うと、従量課金制のためイニシャルコストが押さえられる事、スケーラビリティが確保されている事、フルマネージドサービスであること、という、他のAWSのサービスでも共通となる利点がメリットと感じられます。 また、標準的なSQLに対応している事もメリットです。 性能的にも、データやクエリーの内容にもよりますが、XLノード 1インスタンスの最小構成でも1日あたり数億件増えるようなテーブルに対するクエリーが数秒〜数十秒で実行できるなど十分な性能を持っています。
なお、Redshiftでは、データの保存は以下の手順で行います。
- S3上に所定のデータフォーマット(CSV/TSVなど)でデータを保存
- Redshiftのcopyコマンドで所定のテーブルにS3のデータを読み込み
Fluentdによるデータ保存

fluent-plugin-redshiftを使う
https://github.com/hapyrus/fluent-plugin-redshiftRedshiftへデータを保存するouput pluginはすでに存在します。ちなみにこちらは先述のハピルス社の方々によって作成されたプラグインのようですね。 内部の動きとしては、Fluentdで受け取ったデータをいったんbufferingし、flushのタイミングでS3に保存→copyコマンドでRedshiftに保存、という流れでRedshiftにデータを登録するようになっています。
設定項目については、githubのREADMEに記載されているサンプルを引用します。
<match my.tag>
type redshift
# s3 (for copying data to redshift)
aws_key_id YOUR_AWS_KEY_ID
aws_sec_key YOUR_AWS_SECRET_KEY
s3_bucket YOUR_S3_BUCKET
s3_endpoint YOUR_S3_BUCKET_END_POINT
path YOUR_S3_PATH
timestamp_key_format year=%Y/month=%m/day=%d/hour=%H/%Y%m%d-%H%M
# redshift
redshift_host YOUR_AMAZON_REDSHIFT_CLUSTER_END_POINT
redshift_port YOUR_AMAZON_REDSHIFT_CLUSTER_PORT
redshift_dbname YOUR_AMAZON_REDSHIFT_CLUSTER_DATABASE_NAME
redshift_user YOUR_AMAZON_REDSHIFT_CLUSTER_USER_NAME
redshift_password YOUR_AMAZON_REDSHIFT_CLUSTER_PASSWORD
redshift_schemaname YOUR_AMAZON_REDSHIFT_CLUSTER_TARGET_SCHEMA_NAME
redshift_tablename YOUR_AMAZON_REDSHIFT_CLUSTER_TARGET_TABLE_NAME
file_type [tsv|csv|json|msgpack]
# buffer
buffer_type file
buffer_path /var/log/fluent/redshift
flush_interval 15m
buffer_chunk_limit 1g
</match>
大別すると、S3の設定(認証情報、保存先情報、等)、Redshiftの設定(認証情報、データベース・テーブル情報、等)、Fluentdのbufferingの設定、の3種の設定を行う形になります。 なお、保存先のデータベース、ならびにテーブルについては、事前にRedshift上に作成しておく必要があります。
設定が終われば、あとは当該pluginに所定のフォーマットに則ったデータを流し込めばOKなのですが、若干データフォーマットにクセがあります。データ形式としてCSV/TSV/JSONなどに対応していますが、いずれについても以下のように {“log”: } という形で対象のデータをJSON(message pack)のデータの中に含めてあげる必要があります。
#csv
{"log": "12345,12345"}
#tsv
{"log": "12345t12345"}
#json
{"log": {"user_id": 12345, "data_id": 12345}}
# "log" は pluginの設定"record_log_tag"にて変更可能
fluent-plugin-jsonbucketを用いたサンプル
上記フォーマットにあらかじめ則ってデータを出力できれば問題無いのですが、既存のログデータの活用などを考えた場合、データの構造を変えるのは既存のサービスに影響を与える可能性があるため若干難題です。 そのため、Fluentd内で既存のデータを {“log”: } のフォーマットに変換するpluginを自作してみました。https://github.com/moaikids/fluent-plugin-jsonbucket 行えることは極めて単純で、
{"a":1, "b":2, "c":3 } -> {"log": {"a":1, "b":2, "c":3 } }
という感じで左辺のようなデータを右辺のような形式に変換するpluginです。 こちらと組み合わせてnginxのアクセスログをRedshiftに保存するサンプルを例示します。
まずnginxですが
log_format ltsv 'time:$time_localt'
'host:$remote_addrt'
'req:$requestt'
'status:$statust'
'size:$body_bytes_sentt'
'referer:$http_referert'
'ua:$http_user_agentt';
ここでは単純化して、上記7つの項目がLTSV形式で出力されているとします。 保存されるログの中身は以下のような形式になります。
time:02/Oct/2013:19:26:31 +0900 host:xxx.xxx.xxx.xxx req:GET /musicians/famous/ HTTP/1.1 status:200 size:2172 referer:- ua:Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53
データ保存先のRedshiftでは以下のようなテーブルが存在するとします。
create table access_log(
time varchar(255),
host varchar(255),
req varchar(255),
status integer,
size integer,
referer varchar(255),
ua varchar(255)
);
Fluentdでの読み込みはin_tailで行い、先述のjsonbucketで形式を変換した上でRedshiftに保存します。
<source>
type tail
tag nginx.access
format ltsv
path /var/log/nginx/access.log
pos_file /var/log/fluentd/nginx_access.log.pos
</source>
<match nginx.access>
type jsonbucket
out_tag redshift.nginx.access
json_jey log
</match>
<match redshift.nginx.access>
type redshift
# s3 (for copying data to redshift)
(snip.)
# redshift
(snip.)
redshift_tablename access_log
file_type json
# buffer
(snip.)
</match>
上記のような形で設定を行うと、FluentdのflushのタイミングでデータがRedshiftに書き込まれるようになります。
flydata
実際のところ、上記のようなFluentd〜Redshiftを連携した環境を自作するのは若干手間がかかりますが、同種の事をより高機能で実現することができるサービスとして、商用サービスではありますが先述のハピルス社が提供している「flydata」というサービスがあります。こちらも参考まで。 http://www.hapyrus.com/ja/products/flydata-for-redshift
Tableauによる可視化
 Redshiftへのデータ保存が終わったら、あとは可視化です。ここでは掲題の通リTableauを紹介します。
http://www.tableausoftware.com/ja-jp
Redshiftへのデータ保存が終わったら、あとは可視化です。ここでは掲題の通リTableauを紹介します。
http://www.tableausoftware.com/ja-jp
Tableauはマウス操作でデータの問い合わせ方法や表示方式を選択していく事でリッチなダッシュボードが手軽に作成できる、非常に使い勝手の良いBIツールです。データの取得方法やキャッシュ方法、描画のアルゴリズム等々に先端的な手法が用いられていると言われており、データ規模がある程度大きくても非常に快適に使用することができます。
ビジネス要件や知りたい情報は刻一刻と変わっていくので、エンジニア/非エンジニアに関わらずSQLやプログラムを書くこと無く迅速にかつアドホックに欲しいデータを簡単に取得出来る環境が、非常に重要です。それを実現する手段の一つとして、Tableauは有力な選択肢の一つと感じています。
可視化手法としては一般的な表形式やグラフ形式の他に、位置情報に基づいた地図上へのデータのプロットについても対応しています。こちらは見た目にも派手で人目を引くので、サンプルとして例示してみたいと思います。
fluent-plugin-geoipによる位置情報の付与
https://github.com/y-ken/fluent-plugin-geoipgeoip pluginは、MaxMind社が提供しているgeoipデータベースを用いて、IPアドレスを基に地域情報の抽出を行うFluentd plluginです。geoipデータベースには有償版もありますが、精度の低めな無償版も存在しており、無償版を使用することで手軽に試すことが出来ます。
なおgeoip plulginを使用するにはC言語版のgeoipと、Ruby版のラッパー実装のインストールが事前に必要になります。以下はCentOS/Redhat系OS向けの、Chefを用いたinstall recipeの例です。
package "zlib" do
action :install
end
package "zlib-devel" do
action :install
end
package "GeoIP" do
action :install
end
package "GeoIP-devel" do
action :install
end
execute "install_fluentd_geoip_plugin" do
command <<-EOH
fluent-gem install geoip-c -v 0.9.0
fluent-gem install fluent-plugin-geoip -v 0.0.4
EOH
user "root"
group "root"
end
先述のnginxのアクセスログをRedshiftに保存するサンプルを拡張し、位置情報についても保存できるようにしてみます。
まず、テーブル定義に以下のように緯度(latitude)、経度(longitude)、ならびに都市名(city)を追加します。
create table access_log(
time varchar(255),
host varchar(255),
req varchar(255),
status integer,
size integer,
referer varchar(255),
ua varchar(255),
city varchar(100),
latitude real,
longitude real
);
Fluentdの設定ファイルにもgeoip pluginを用いた地域情報の変換処理を追加します。nginxのアクセスログの情報のうち、”host” に含まれているIPアドレスを使用して地域情報を抽出します。
<source>
type tail
tag nginx.access
format ltsv
path /var/log/nginx/access.log
pos_file /var/log/fluentd/nginx_access.log.pos
</source>
<match nginx.access>
type geoip
geoip_lookup_key host
enable_key_city city
enable_key_latitude latitude
enable_key_longitude longitude
add_tag_prefix geoip.
</match>
<match geoip.nginx.access>
type jsonbucket
out_tag redshift.nginx.access
json_key log
</match>
<match redshift.nginx.access>
type redshift
# s3 (for copying data to redshift)
(snip.)
# redshift
(snip.)
redshift_tablename access_log
file_type json
# buffer
(snip.)
</match>
Tableauでの操作方法は割愛しますが、Tableau上で上記のRedshiftのテーブルの接続設定を行うとlongitudeとlatitudeが自動的に地域情報として認識され、集計対象のカラムがメジャー情報(数を集計する対象の情報)として認識されます。それらを組み合わせると以下のような地図を作成することができます。
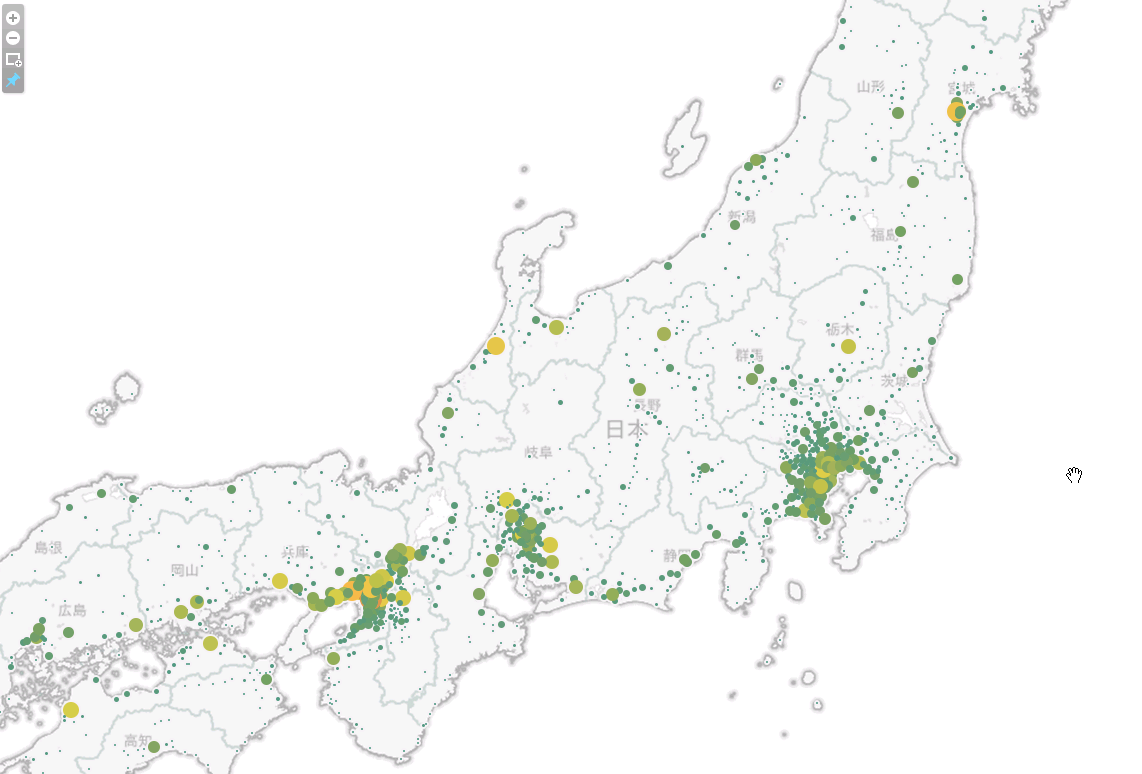
まとめにかえて
データの分析はどんな業態、どんなレイヤーの人間にとっても非常に大事で、いかに効果的で使われるシステムを構築するかは我々のようにサービスを開発運営していく立場においても大事です。よりよい環境を構築する為に弊社が取り組んだ施策の極一端を紹介させていただきました。システムの観点で言うと、大量のデータを安定して保存し、高頻度で解析していくためには、技術的なバックボーンとノウハウの習得が必要となってきます。今回は文量的な制約もあり表面的な話のみ記載をしていますが、その裏には技術的に様々な試行錯誤があることをご察しください。
今回は商用ソフトを用いた事例となりましたが、OSSの組み合わせで言うと最近技術者の間でトレンドとなっている「Fluentd」「elasticsearch」「Kibana」を用いたログ分析の可視化も非常に面白い組み合わせと思います。 [参考] Kibanaってなんじゃ?(Kibana+elasticsearch+fluentdでログ解析)
また、今回の事例では紹介いたしませんでしたが、データの保存先・解析プラットフォームとしては、Treasure Data社が提供しているプラットフォームが技術的にも将来性としても非常に魅力的です。 http://www.treasure-data.com/
Hadoop界隈においてもMesosやSparkなどの並列分散処理系周りの動向も活発で、データ解析に関する分野は非常にレッドオーシャンな感じで盛況なので、常に新しい情報のウォッチが必要な分野と感じています。
なお、今回記事中に”さだまさし”ネタが含まれておりませんが、特に上司に怒られたとかそういう事は一切なく、単にネタ切れである事を謹んでご報告申し上げます。