大平です。今回はさだまさしネタは特に無しです。
先日、サービスのクローラーで使用しているID生成器について置き換えを行いました。非常に地味な話になりますが、本記事ではその辺の内幕の話をしたいと思います。
ID生成にまつわる苦悩
弊社ゴクロの提供しているSmartNewsは表向きはニュースアプリですが、裏側の仕組みは検索エンジンに近似しています。ユーザーの方々の興味関心や、アクセス傾向をクエリーとし、その内容に応じた話題のニュースを検索結果として返却する、という風に捉えていただくと、なんとなく私が言わんとしている事を想像していただけるかと思います。SmartNewsはTwitterのつぶやき情報を用いたトレンド分析をベースとしており、話題になっているニュースを選定するためには、大量のTwitter上のtweet、ならびにその中に含まれているURLに対してクロールを行う必要があります。日々配信しているニュース記事の候補は1日あたりせいぜい数千記事程度ですが、実際はそれよりも何桁か多い規模のURLをクロールしています。
そういった状況において、意外と重要で、軽視出来ないのがIDの採番です。当然、クロールしたすべてのURLに対して一意となるIDを割り当て、内部で管理する必要がありますが、概ね以下3点について課題がありました。
- ID生成器の性能
- IDの利便性、再利用性
- IDのデータサイズ
また、MySQLのauto incrementでは、内部のカウンターを順次インクリメントしていくだけなので、時間軸に伴った採番の順序性は保てますが、それ以外の用途に応用が難しいです。そうではなく生成したIDからIDの生成された日時などを復元できたりすると、利便性も向上しますし、用途によっては別途timestamp情報を保持する必要もなくなり全体としてのデータの省サイズ化にも貢献できます。
あわせて、大量のデータをクロールしているため、IDのデータサイズについても小さければ小さいほど全体のデータ効率が良くなります。
まとめると、直面している課題を解決するための要件としては以下のようになります。
- SPOFではない分散環境で一意なIDを生成できる仕組み
- IDはtimestamp を基にしたもので、ID情報からtimestampを復元可能(Time-basedなID)
- 出来る限り小さいデータサイズでIDを表現
snowflake

snowflakeはscalaで書かれたID生成器で、thriftの仕組みなどを用いて分散環境で並列ID生成が行えるように作られたもののようです。
snowflakeではlong値(64bit)としてIDを表現します。実際は、unsigned long / signed long いずれの環境でも特に細工なく使用できるようにするためか、63bitの範囲で表現しているようです。 bit layoutは以下。
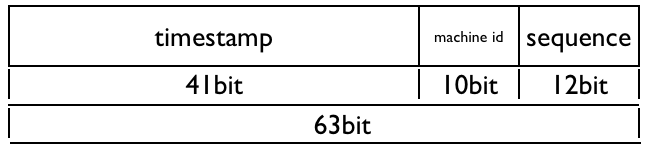
- timestamp(41bit) : 現在のunixtime(milliseconds)から、ある時点のunixtimeを引いた値
- machine id(10bit) : 生成器ごとに割り当てられたID
- sequence(12bit) : 生成器ごとに採番するsequence番号
ざっくり言うと、全体としての一意性はtimestampとmachine idで担保し、生成器内での一意性はsequenceで担保している、という設計になってます。
timestampの値は本来は64bitですが、ある時間以降に発行するIDについてはある時間以前の情報は不要になるため、所定の日時のunixtimeを引いた値を41bitの値として使用します。ある意味思い切った割り切りですが、実運用上はこれでbit数の節約が行えます。 なお、41bitのtimestamp値がoverflowするのは採番開始からおおよそ69年後となるため、実用的な意味では特に問題は起こらないようです。
snowflakeでは以下抜粋したコードで示すように現在日時から1288834974657を引いた値を扱っています。
var twepoch = 1288834974657L // Thu Nov 04 10:42:54 JST 2010
var timestamp = System.currentTimeMillis()
var time = timestamp - twepoch
shakeflake

「snowflakeを使えば良いだろ」という声も聞こえてきますが、snowflakeは大規模な環境で使用される事を想定しているように見受けられ、若干重厚です。 bit layoutを環境に応じて少し調整したいという思惑もあり、ID生成部に関しては単純な仕組みになっている事もあったので、社内で「shakeflake」と呼んでいるツール群を自作をしてみました。
ちなみに、名前の由来は僕が鮭フレークを好きだから、です。アツアツご飯に乗せるだけ〜。
Redis + Lua Scripting版 shakeflake
Redisは2.6以降からLua Scriptingに対応しており、任意の処理をサーバーサイドで実行できるようになりました。こちらの仕組みを用いて、snowflakeと似たようなID生成を行ってみました。以下導入手順について解説します。まず2.6以降のRedisをインストールする必要があります。 http://redis.io/download なお、Scripting処理はevalコマンドを用いて行います。 http://redis.io/commands/eval
次に、Redis nodeのnode id と sequence 情報を表現するための入れ物を用意します。 ここではnode idのkeyは”node_id”, sequenceについては”sequence”とします。 Redisを複数台用意する場合は、node_idのvalueは各Redis serverごとに異なる数値を割り当てます。
$ redis-cli set sequence 1
$ redis-cli set node_id 1
続いて、ID生成処理を行うLua Scriptingを用意します。Lua内部でsequenceをインクリメントし、自分自身のnode_idの値を取得し、timestamp - epoch の値とを組み合わせてIDを生成しています。
-- id.lua
local epoch = 1288834974657
local seq = tonumber(redis.call('INCR', 'sequence')) % 4096
local node = tonumber(redis.call('GET', 'node_id')) % 1024
local time = redis.call('TIME')
local time41 = ((tonumber(time[1]) * 1000) + (tonumber(time[2]) / 1000)) - epoch
return (time41 * (2 ^ 22)) + (node * (2 ^ 12)) + seq
その上で以下のようにevalコマンドでLua Scriptを実行すると、ID値が生成されます。
$ redis-cli --eval id.lua
(integer) 347205555082385408
手順は以上です。
JavaVM版 shakeflake
…と説明をしてきましたが、実際は現場ではRedis+Lua Scripting版は使用していません。 Redis+Lua Scripting版も十分高速ですが、どうしてもネットワーク接続のオーバーヘッドは避けられません。社内で使用する上では環境のポータビリティはあまり気にしなくて良く、稼働しているJavaアプリケーションと同じJavaVM上に組み込んだ方が性能面で有利なので、最終的にはJavaで書いたコードを基にID生成を行なっています。なお、細かい例外処理の追加やJava向けの最適化はしていますが、基本的にはsnowflakeやLua Scriptingでのロジックと同じような中身になっています。machine idの取得のみネットワーク経由で行いますが、それ以外はJavaVMの閉じた空間の中でID生成されるため非常に高速です。
性能比較
開発用のMacbook Proを使用して、単純な条件で性能比較を行なってみました。- 条件:10,000件のIDについて逐次発行処理を行う
- マシン環境:2010年に発売されたMacbook Pro(memory 8GB / CPU Intel 2.66GHz Core 2 Duo / 128GB SSD)
- ミドルウェア環境:
- MySQL : 5.5.30
- Redis : 2.6.13
- Java : 1.6.0_51
| MySQL | Redis+Lua Scripting | JavaVM | |
|---|---|---|---|
| 試行回数 | 10,000 | 10,000 | 10,000 |
| 処理時間 | 220,000ms | 1,636ms | 16ms |
| 1回あたりの処理時間 | 22ms | 0.16ms | 0.0016ms |
上記は単一の生成器を用いた性能比較ですが、shakeflakeでは複数の生成器を用いて並列にID生成が可能なので、台数が増えれば増えるほど時間当たりのID発行性能は線形に向上します。
運用面で気をつけるべきこと
snowflakeのREADMEにも書かれていますが、このID生成方法はOSのSystem Clockに大きく依存しています。そのためOSの時刻がズレたときの挙動について気をつけておく必要があります。 具体的に言うと、過去から未来方向にズレが補正された場合は基本的に問題無いですが、未来から過去方向に補正された場合、過去に発行したIDとこれから発行するIDが重複する可能性があります。 対応策としては、過去方向に時間が補正された場合は例外を発行するなどして当該生成器でのID生成が行われないようにする、もしくは直前までのtimestampを用いてsequenceが枯渇するまでIDを生成しtimestampが未来のものになるまで粘る(枯渇したら例外発行)、等が考えられます。また、単一生成器内で、1ミリ秒以内に4096回以上IDの生成を行うと、sequenceがoverflowしてしまう可能性があります。 なので、「生成器数 × 4096回 / ms」 以上のオーダーでID生成が行われそうな場合は、逐次ノードを増やしていく必要があります。
また、IDの重複に関しては、上記の仕組みだけでは検知できないので、生成したIDを取得した側で重複チェックを行う必要があります。
実際のところ、一意のIDを少ないビット量で表現するのにはどうしても制約がつきまとうので、運用には工夫が必要になるとは思います。それでも性能面での利得が大きいため、このような方法を用いてIDの生成を行なっています。参考になりましたら幸いです。
Appendix. “A Universally Unique IDentifier (UUID) URN Namespace”
以上でshakeflakeについての説明は終わりですが、おまけとして、一般的に用いられるUUIDの仕様の一つとして、RFC4122で定められている仕様を簡単にご紹介します。RFC 4122に準拠したID生成器は多くのプログラム言語に実装されていますし、実際にMicrosoftのGUIDなどのように多くの製品に使われています。 http://www.ietf.org/rfc/rfc4122.txtRFC4122 UDIDは用途に応じて5つの種類のversionが用意されており、そのうちversion 1がTime-basedなUUIDになります。種類の一覧は以下。
| version | description |
|---|---|
| 1 | The time-based version specified in this document. |
| 2 | DCE Security version, with embedded POSIX UIDs. |
| 3 | The name-based version specified in this document that uses MD5 hashing. |
| 4 | The randomly or pseudo-randomly generated version specified in this document. |
| 5 | The name-based version specified in this document that uses SHA-1 hashing. |
| time_low | 32 bit |
| time_mid | 16 bit |
| time_hi_and_version | 16 bit |
| clock_seq_hi_and_rese | 8 bit |
| clock_seq_low | 8 bit |
| node | 48 bit |
{kind=link}
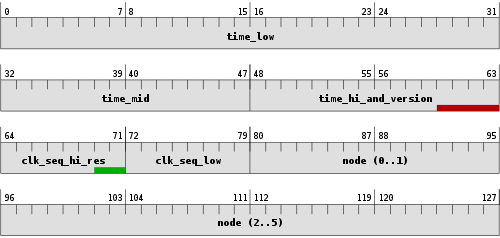
time_hi_and_version の部分にはversion番号についても含まれ、clk_seq_hi_resの部分にはvariant番号が含まれます。 (※variant番号:どのUUID仕様に準拠しているかを表す値。RFC4122に準拠する場合は先頭2ビットが”10”。MicrosoftのGUIDの場合は先頭3ビットが”110”)
time_low / time_mid / time_hi_and_version の部分はtimestampをベースとして生成される部分で、snowflakeなどにおけるtimestampにあたる部分です。 同様に node は machine id、clk_seq_hi_res / clk_seq_low は sequenceにあたります。
なので乱暴に言ってしまうと、RFC4122 UUID(version 1) とsnowflakeのようなIDは、基本的には同じような考え方のもとにbit layoutが設計されたIDになります。 もちろんRFC4122 UUIDの方がビット長が長いため、より堅牢なIDになります。
JavaにおけるUUIDの作成
Java には java.util.UUID というクラスが存在しますが、こちらはversion 3、ならびにversion 4にのみ対応しています。version 1対応のIDを作成したい場合は、独自にロジックを書く必要があります。 なおversion 3ならびに 4の生成方法は以下のようになります。// version 3
String seed = "tekitounaatai";
UUID version3 = UUID.nameUUIDFromBytes(seed.getBytes());
//version 4
UUID version4 = UUID.randomUUID();
一応、拡張ライブラリとして、Apache Commonsが提供しているCommons IDなどを使用すれば、Javaでも version 1のUUIDを手軽に生成することができます。
PythonにおけるUUIDの生成
Pythonでは”import uuid”をすることでUUIDの生成が行えます。Pythonは標準でversion 1にも対応しています。>>> import uuid
>>> print uuid.uuid1()
d6404f1e-f84c-11e2-9652-f80121feed7e